Data | Domains
Aftermovie PyData 
Walter van der Scheer 01 Apr, 2016





Before you start to complain that Big Data is a highly overloaded term, I think that regardless of whether that is true, we will have to learn to live with it for now. The term Big Data is going to stay with us for a while. Here’s why:
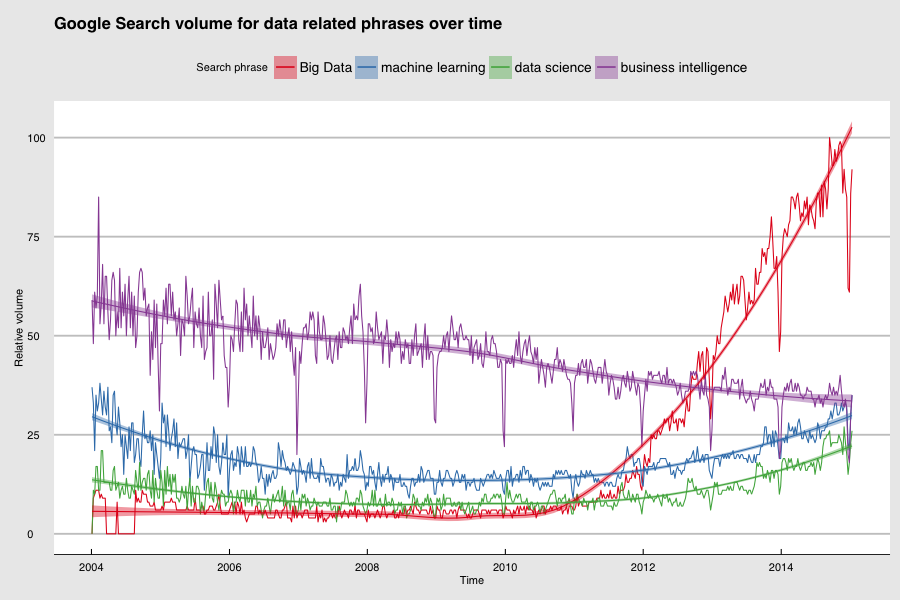
Source: Google Trends.
Clearly, interest is peaking and people are in a buying mood. When people are in a buying mood, companies are selling. The companies that are selling have entire departments dedicated to making sure that we hear about it (a.k.a. marketing), hence: I think we will be hearing about Big Data for some time to come. Let’s have a look at how we got there and what we can do to benefit.
Back in 2009, I was part of a team working on indexing and retrieval of high volume network data collected by our customer. Their existing solution of sharding MySQL databases worked, but was tedious to maintain and was coping with scalability issues, so we were trying Apache Hadoop and HBase as a replacement. Both of these technologies were difficult to maintain at best and would fail with cryptic error messages at seemingly random moments until you would spend some time reading the actual source code and figured out how things really worked. On top of that, the software wasn’t spectacularly efficient in what it did; it didn’t squeeze all possible performance out of the machines it would run on. However, in spite of these quirks, Hadoop and HBase did one key thing above anything else: they scaled.
Hadoop and its MapReduce implementation provided a generally available, open source, scalable abstraction that allowed developers to focus on their data processing code.
In essence it meant that it didn’t matter whether you were coding a job for a cluster of two machines or a cluster of two hundred machines; the same code would run equally on both. If you have a lot of data and you don’t know how fast it will grow, that means a lot. Not to mention that there was a lively community of people working on this open source software who would answer questions on mailing lists in a manner far superior to most commercial support offerings available for database software. We spent a lot of time setting up clusters, debugging issues and there was a fair amount of trial and error. In the end, things worked relatively well; as with most software projects, we made it work.
Not too much later, Hadoop was gaining traction as large web properties were reporting sucesses with the technology. The critics were busy pointing out the practical problems, while people who understood the theoretical possibilities were working hard to improve the software. That’s also when the departments dedicated to making sure we hear about things caught on, started calling it Big Data and made extra sure everybody knew about the three, four or five V’s that ought to be associated with it. (Note that the original report that first listed the three V’s doesn’t have the term "big data" in it anywhere.).
Meanwhile, the people who actually benefited from the technology weren’t too concerned with which of the V’s their problems embodied, but were mostly interested in getting things done. It was as if there was a Big Data world, led by the likes of Gartner, and a Hadoop world, led by engineers. Companies that already had scalability issues with their data were looking into Hadoop as a solution, while companies that were managing just fine, but afraid to miss out on Big Data were working hard to invent use cases that would fit them. While the latter may seem silly, it isn’t at all as wasteful as it may sound. These initiatives were driving innovation and forcing traditional companies to re-evaluate some of their business, looking into new directions. In most of these cases the fact that Hadoop can handle large volumes of data wasn’t the interesting outcome. Instead it was the fact that much of the available data within organisations could be used in ways other than its intended purpose and lead to new ways of doing business or approaching customers. In some cases, a platform like Hadoop wasn’t required technically, but helped create a climate for innovation; it made people think about using data differently.
The magic of Big Data is, supposedly, that you can get interesting and significant results using very simple methods and models, as long as the data volume is very large. The patterns just emerge. One example of this is the Google Trends graph on top of this post. We can make statements about the relative public interest in these subjects, based on the assumption that there is a relation between peoples’ search behaviour and real-life events and trends. In this case we do not care about the causality of this relation. The method used is extremely simple: count the number of times a search occurs, yet the results are interesting because of the immense volume of the data.
If you wonder about the relation between Google searches and real-life events, below is an example that is hard to deny. In the chart below, the dots on the blue line indicate the relative week-by-week volume of searches for the phrase "full moon". The weeks in red dots are weeks when a full moon occurred, the weeks in blue dots the remaining ones. There’s a very clear relation between the search volume and the real-life event. It’s easy for us to understand that the searches are not causing a full moon, just as the searches for Big Data are not causing the interest in the subject. For a model that predicts the next full moon (or wave of interest in a topic), however, this isn’t relevant. You can just count words on the internet to make statements about the real world: Big Data at its finest.
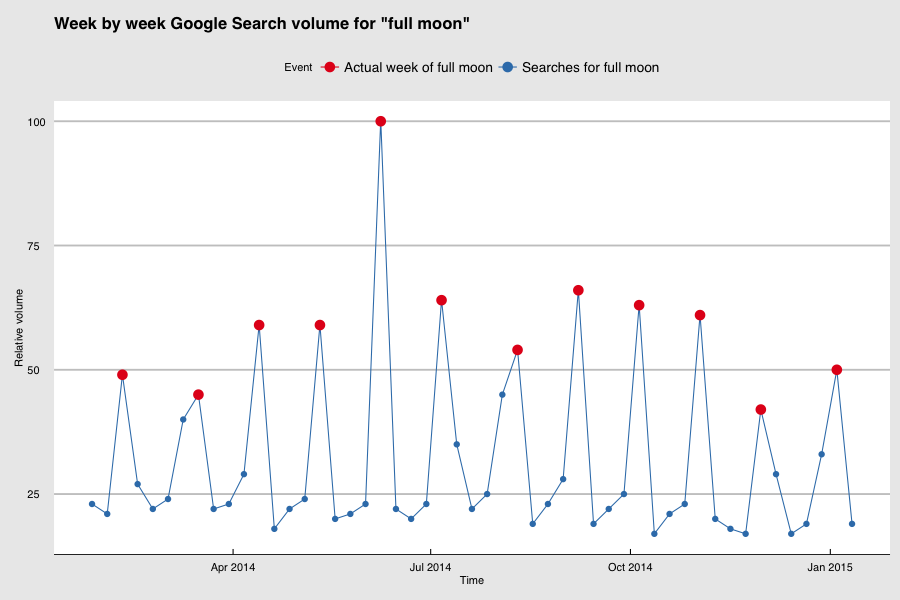
Source: Google Trends and moongiant.com. Note: Google Trends only exposes week-by-week data, so the full moon dates are normalised to the start of the week they occured in as well.
As it turns out, while the above examples are nice, counting words on the internet doesn’t solve everybody’s business problems. We want to make more granular predictions than those about the entire population of Google users. We care about our own customers or communities of users, because they have come to expect a very high level of personlisation and customisation in our products. Yet the data that we collect on these customers is typically very sparse. As a online retailer you may have millions of visitors, but each of those visitors individually might only visit your shop once or twice a year. Nonetheless, we are supposed to send them personlised e-mail campaigns, provide spot on product recommendations and be able to tell whether there is opportunity for up-sell or cross-sell. All of this based on those one or two visits per year.
The total amount of data can be very big, but the amount of information on individual customers is limited. To still provide spot on personalisation in this scenario is a very hard problem and goes far beyond counting words: Data Science and machine learning come into play.
It’s no surprise that in our search trends, we see these disciplines gaining popularity compared to more traditional data related work, such as business intelligence.
The skills required to work on Data Science and machine learning problems are scarce and the combination of these skills with the ones required to deal with large data volumes from an engineering perspective even more so. This is why we started GoDataDriven. We help our customers get started on this track. Also, these complex models and methods are a lot more computationally intensive than just counting words. Luckily, there we are in a good spot.
Many of the methods currently used in large scale machine learning are years if not decades old. Of course there are recent refinements and additional research, but the baseline has been around for a long time. Two things have changed: we have more data and we have better means of processing it.
It’s not so much that we weren’t able to build powerful computers before, but the economy of scaling computer systems has changed drastically.
Every now and then, the internet quips something about that phenomenon:
“‘If you had bought the computing power found inside an iPhone 5S in 1991, it would have cost you $3.56 million.'” http://t.co/Z2b1zKcn4J
— Steven Sinofsky (@stevesi) December 23, 2014
With or without two year subscription. It wouldn’t exactly have been pocket size either.
While this number might not be accurate to the dollar, the order of magnitude is likely correct. The amount of processing power in your pocket used to be a multi-million dollar computer at some point in time; probably during your lifetime.
Below is a chart for which the data was collected initially by John C. McCallum and later amended by Blok, who also created this chart. Note that the vertical axis has a log scale!
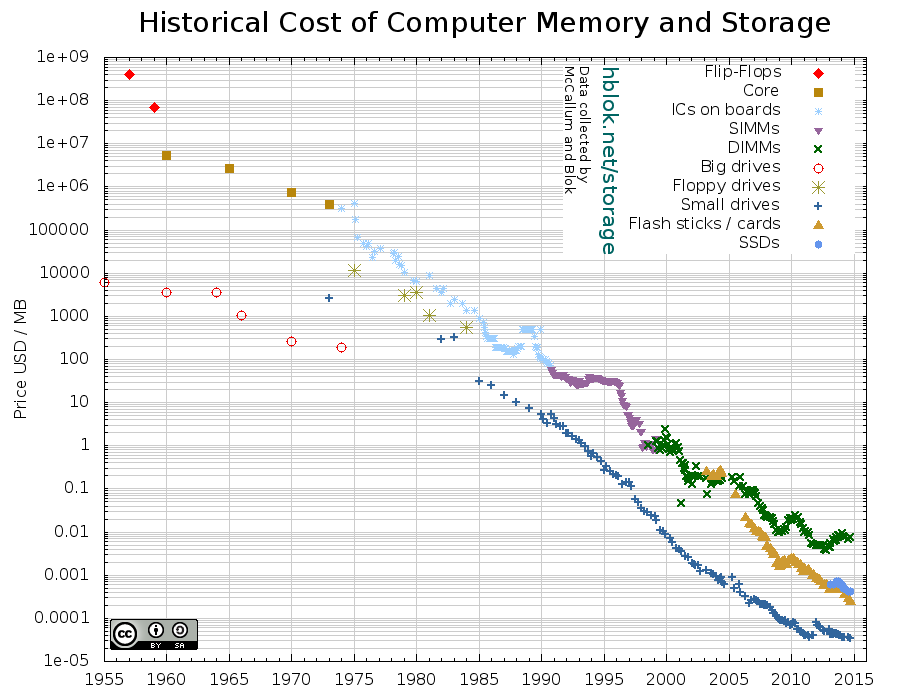
Source and image credit: http://hblok.net/blog/storage/.
There’s a few things worth noting here (in no particular order). When Google released their MapReduce paper (2004), spinning hard drives were more expensive than SSDs are now. The first Hadoop release was in September 2007. At that point spinning hard drives were more or less on par with today’s SSD pricing. The lowest price seen for memory (RAM) is roughly on par with the prices for spinning disks in 2001.
So, however you look at it: in-memory computing is a attractive option for many problems that were previously on-disk problems. Same goes for using SSDs instead of spinning hard drives. Reading data from a SSD is about 6-7 times faster than reading from a spinning disk. Reading data from memory is about 105 times faster than reading from a spinning disk and 15 times faster than reading from SSD. (Latency numbers courtesy of this website).
All of this means that some problems that used to be cluster scale problems (i.e. too big for a single machine to solve), are now single machine scale problems. The issue is that it is a moving target which class of problems you have at hand; machines are getting cheaper and faster, but data is growing and the methods and models that we run are getting more complex. This calls for the type of scalability that Hadoop has provided; to be flexible, it shouldn’t matter if your code runs on two machines or two hundred.
(Warning Technical content ahead. The following section contains references to technical concepts and code. If you only care about the resulting business recommendations, feel free to skip down to the conclusion all the way down.)
While it is true that for early Hadoop MapReduce it didn’t matter whether your code would run on two machines or two hundred, the former case wasn’t something you would really do in practice. There is always overhead associated with distributed computing and the overhead of Hadoop MapReduce was so large, that it would only really make sense to run Hadoop on at least 20 machines or more. Besides that, MapReduce depends heavily on disk IO and makes only minimal assumptions about the presence of a lot of memory (the thing that’s gotten a lot cheaper lately). As a result, people have been working on other processing abstractions that do a better job of utilising available memory and only fall back to disk IO when required by the work load. When distributed computing starts to utilise memory and faster storage, it starts to make sense to also focus on optimising the parts of the program that are not parallelised across the cluster, such as the startup of jobs (see Amdahl’s Law). The startup overhead of a Hadoop MapReduce job on the early versions was on the order of 30 seconds. Right now it’s closer to 5 seconds. Apart from MapReduce, other frameworks have emerged that run on top of the Hadoop storage architecture and have further optimised the cost of paralellism and the use of memory and faster disks. One such framework is the popular Apache Spark project.
If it is the case that these new abstractions make better use of memory and have lowered the overhead of paralellism, it should be realistic to use very small clusters or even single machine setups, but with a scalable abstraction that can potentially scale to large clusters. This would put us in the position where we can again focus on the data processing code without being concerned with the scalability, but as additional benefit, would allow us to start small (with a single machine, not a cluster). Let’s put this to a test.
Below is a table of the wall clock time it takes to run simple Apache Spark code snippets against a data set of 600 million records, accumulating some 40GB of raw data. These numbers are in no way meant to be representative for the used framework and can be optimised a lot further given relatively simple efforts (such as using a binary file format and compression). These tasks were run on a single machine with 2x 10 CPU cores, 128GB RAM and 2x 1.6TB SSD drive in RAID0 configuration. Such a machine can for example be rented from Rackspace as part of their OnMetal offering. At the time of this writing, this setup costs USD 1,750.- per month or about USD 2.5 per hour, which puts it at USD 21,000.- per year. With no license costs, this is price is not far from a typical heavy weight database machine including licenses as often used for datawarehousing purposes. Other cloud providers or on-premise hosting shouldn’t be far from this price point.
| Task | Time | Code |
|---|---|---|
| Read file and count 600M lines |
val tf = sc.textFile("/mnt/raid/numbers.txt")
tf.count | |
| Read file, parse CSV and count 600M records |
val data = tf.map(_.split('|'))
.map(line => (
line(0).toLong, line(1).toLong,
line(2).toLong, line(3).toLong,
line(4).toLong, line(5).toDouble,
line(6).toDouble)
)
data.count | |
| Summary statistics over 600M floating points |
import org.apache.spark.SparkContext._
data.map(_._5.toDouble)
.stats
| |
| Low cardinality group by key + count |
data.map( x => (x._3, 1) )
.reduceByKey(_ + _)
.collect
| |
| Top 10 of high cardinality column with long tail distribution |
data.map( x => (x._4, 1) )
.reduceByKey(_ + _)
.map(List(_))
.reduce( (x,y) => (x ++ y).sortWith(_._2 > _._2)
.slice(0,10))
| |
| KMeans clustering on ~60M cached 2D vectors Note: clustering took two iterations to converge. Add about 4 seconds for each consecutive iteration. Time does not include taking the sample and caching. |
import org.apache.spark.mllib.clustering.KMeans
import org.apache.spark.mllib.linalg.Vectors
val clusterData =
data.sample(false, 0.1)
.map(
t => Vectors.dense( Array(t._6, t._7) )
)
clusterData.cache
clusterData.count //returns 60011237
val clusters = KMeans.train(clusterData, 4, 10)
|
Time is wall clock time. Data was generated using this code. Spark was configured to run 12 workers with 2 cores each, using a maximum of 8GB heap per worker.
These results mean that complex data analysis jobs against 600 million records are likely to run in minutes, not hours. When volumes grow or complexity grows, it is possible to run the same code on a cluster of computers with the ability to dynamically expand capacity. This can allow for a lot of flexibility.
So, what does it all mean? Big Data is still a hot topic. Hadoop and its ecosystem of tools and frameworks has evolved to a reasonably efficient technology for scalable computing. The initial promise of Big Data that we would rule the world by counting words didn’t completely come trough, but with more complex models we can do very interesting things with data that was previously collected for other purposes. We don’t hear too much about the V’s anymore, but data science, machine learning and analytics are the new black. Now, where do you put your money?
Right now, we really are at the point where we can focus on data driven products: using a combination of data science and engineering to create a better experience for customers. Scaling data processing is a solved problem. Computers are indeed fast and cheap, often you can get started with data on a commodity laptop. Data science is a real thing (and of course, we can help you get started). There is now an opportunity to combine these developments into better products. It’s safe to stop talking about the V’s of Big Data and join the early wave of organisations actually benefiting from the technology.
My first piece of advise: start with the people, not technology. Without people around that know how to interpret it and build solutions on top of it, it doesn’t matter how big your data is. The technology side of things is really a solved problem (for most of our purposes, anyway). Try to create a climate that allows you to hire data scientists and high quality engineers (this is what we do). Encourage innovation and experimentation. Don’t just build a Hadoop cluster, because you can.
Secondly, focus on general availability of data over correctness. Make it the responsibility of whoever uses the data to decide whether it’s fit for purpose. Whether you call it a data hub, data lake, data warehouse or virtualised data store or something else, you need a central place where people working with data can access the raw source data that describes what happens in your organisation.
Last but not least, have a collection strategy. Data collection in products is in many cases an afterthought. Often this is then outsourced to external service providers, yet you should be careful to retain ownership of your own data. If you have a high volume website, but are sending your clickstream data to Google through Google Analytics, you are giving away one of your assets while paying for it at the same time (not to mention legal and privacy issues that can arise when your customer data goes out of your control).

