Data | Domains
Aftermovie PyData 
Walter van der Scheer 01 Apr, 2016





Update May 2017: Instead of provisioning the Druid database in the CI job, the Druid Docker build is now pre-provisioned in the Dockerfile itself using a handy script.
At GoDataDriven we have an open source first culture, we love to use and contribute to open source projects. This blog gives an example of how we integrated Druid in a continuous integration (CI) pipeline. Like software engineering, the world of data engineering requires continuous integration to quickly and confidently deploy new versions of your software.
One popular way of testing external dependancies is by the use of mock objects. Personally I’m not a huge fan of mocking because it might not reflect the actual behaviour of the external component. Furthermore it might be interesting to test the software against different versions of the database.
For those unfamiliar with Druid. It is a high-performance, column-oriented and distributed data store. Druid indexes data to create immutable snapshots, optimized for aggregation and filtering, aiming at sub-second queries over massive volumes of data. The main focus is on both availability and scalability and the architecture does not have a single point of failure, this enables Druid to scale in a lineair fashion by adding more nodes to increase capacity in both of volume and queries. Looking from the perspective of the CAP theorem, Druid does not need to handle consistency because Druid does not support writes. Therefore the main focus on partition tolerance and availability. Druid is partially inspired by existing analytic data stores such as Google’s BigQuery/Dremel and Google’s PowerDrill.
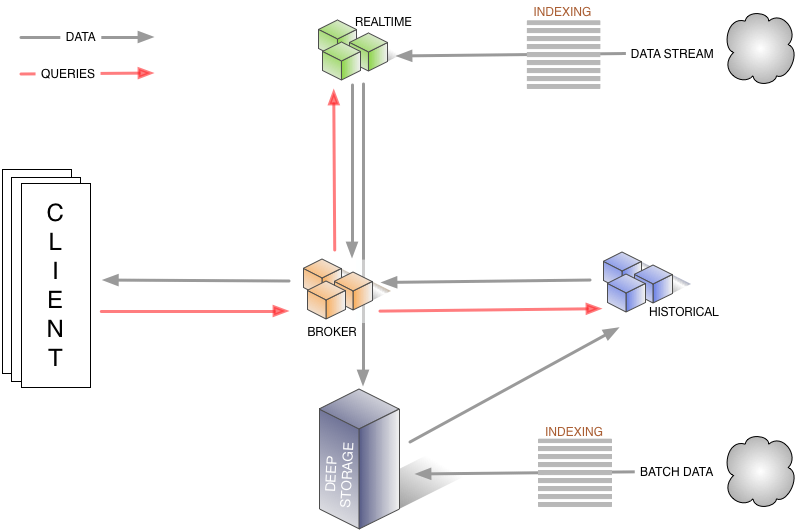
By looking at the image above, the architecture of Druid is rather complex if you compare it to a single relational database like Postgres or Mysql. It consists of a variety of roles which have different responsibilities. For example, the broker node is responsible for handling the queries and consolidating the partial results retrieved from the historical nodes and will return the final result. The historical nodes plow through the data which is split in segments, loaded from a deep store, such as HDFS, S3 or Cassandra. Beside the roles mentioned in the drawing, there are even more supporting processes, such as the coordinator and overlord, which is responsible for ingesting and distributing the blocks among the different historical nodes. For a more in depth view of the architecture, please read the Druid paper.
Druid itself provides a complete Druid cluster within a single container using supervisord. Although it does not make any sense to use this image in production, it is nice to explore the possibilities of druid or, use the container within a CI environment. The modified version of the Druid container that we’ve developed ingests a dataset when building the image. This could be a sample set that represents the production dataset and can be used to test your application against. The container ships by default with the wikipedia dataset, but it is also possible to create a new dataset by ingesting your own data. From our findings, we also proposed some pull requests to give our findings back to the community, to be specific, 27, 29, 30, 31 and 32.
For this blog I’ll be using our Gitlab repository in combination with Gitlab CI runners, which is my preferred CI runner. Gitlab uses Docker and allows us to spin service containers, which are linked containers providing external dependencies, in our case Druid from the Docker Hub. The CI job is defined in the .gitlab-ci.yml which resides in the root of the repository.
Before starting the actual CI stage, the services containers defined under services in the yaml as shown below, will be started. The service containers will be resolvable using a hostname which is related to the actual image name, only the / is replaced by a double underscore __, for more information please refer to the Gitlab CI documentation.
image: python:2 druid-ci: services: - fokkodriesprong/docker-druid script: - echo "Up and running" - pip install -r requirements.txt - flake8 - ./provision.py --file wikiticker-index.json --druid-host fokkodriesprong__docker-druid - python -m pytest tests/druid.py --druid-host fokkodriesprong__docker-druid
Both the Druid container and the Python base image start from a clean image, so first we install some python packages using pip, second we provision the druid data source, and finally we can test the application against Druid. We also do a flake8 code style check to make sure that the code is formatted against the pep8 standards.
The image is already provisioned using a handy script. During Docker build time we provision the image by submitting a json file against the overlord/coordinator node of the Druid cluster, which will dispatch the job to the middle manager node. In this case we take a predefined json from the repository itself, but for production it would make more sense to take the actual production definition of the druid data source and modify it slightly with jq to make it work in the CI environment. The script will monitor the indexing process and the actual loading of the data source to make sure that the data is loaded properly, otherwise a non-zero exit code will be thrown. Now the data is loaded and the Druid container is booted, we will fire a query to Druid:
{
"queryType" : "topN",
"dataSource" : "wikiticker",
"intervals" : ["2015-09-12/2015-09-13"],
"granularity" : "all",
"dimension" : "page",
"metric" : "edits",
"threshold" : 5,
"aggregations" : [
{
"type" : "longSum",
"name" : "edits",
"fieldName" : "count"
}
]
}
Next we use pytest to execute two test cases against the druid server. First we check if the data source is available, and second execute a topN query against Druid. This ensures that the queries of the application are compatible with the current data schema and version of Druid.
That’s all for now. As always, we’re hiring Data Scientists and Data Engineers. Head up to our career page if you’re interested. You get plenty of opportunities to give back to the community.

