Data | Data Science and AI
White paper: The big data revolution 
Friso van Vollenhoven 18 Apr, 2011





At the Dutch Data Science Week I gave a talk about Fairness in AI. The impact of AI on society gets bigger and bigger – and it is not all good. We as Data Scientists have to really put in work to not end up in ML hell!
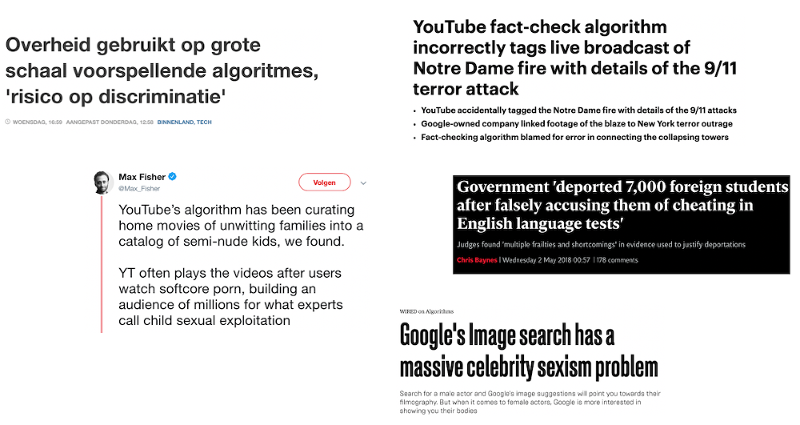
Ethnic profiling by the Dutch tax authorities is a recent example of algorithmic (un)fairness. From a news article in newspaper NRC:
“A daycare center in Almere sounded the alarm when only non-Dutch parents were confronted with discontinuation of childcare allowance [..] The Tax and Customs Administration says that it uses the data on Dutch nationality or non-Dutch nationality in the so-called automatic risk selection for fraud.”
Targeting non-Dutch parents while leaving Dutch parents untouched is a clear example of unfair fraud detection! Dutch authorities responded that this mistake had already been fixed:
In a response, the Tax and Customs Administration states that the information about the (second) nationality of parents or intermediary is not used in this investigation [..] “Since 2014, a second nationality with Dutch nationality is no longer included in the basic registration. This has been introduced to prevent discrimination for people with dual nationality.”
Not using the nationality seems like a good step, but is this enough to get fair decisions? Probably not: biases can still be encoded by proxies in the dataset. For instance, Nationality can still implicitly be encoded in the data by occupation, education and income. We need to actively remove fairness from the system.
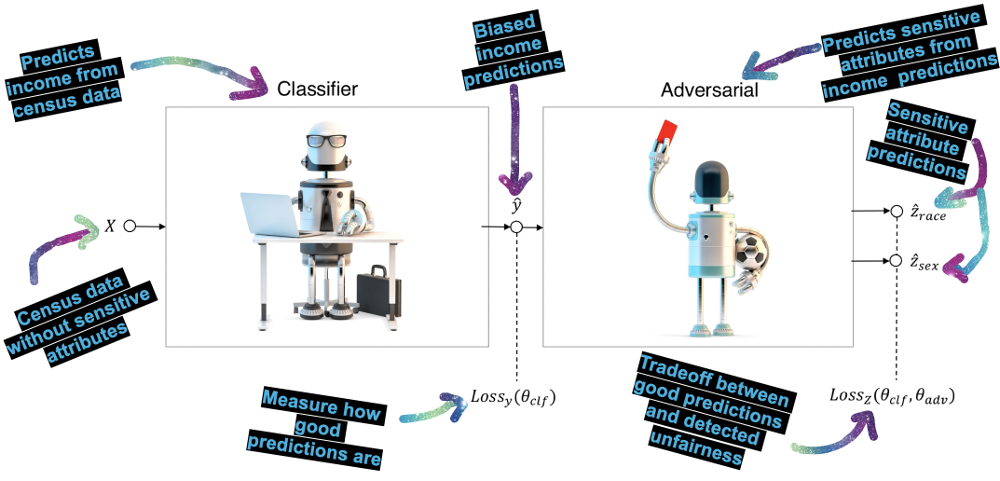
In my talk at the Dutch Data Science Week, I showed how to enforce fairness by using a fairness referee. We start out with a standard classifier but give the output to an adversarial classifier that acts like a referee. This referee tries to reconstruct bias from the predictions and penalizes the classifier if it can find any unfairness.
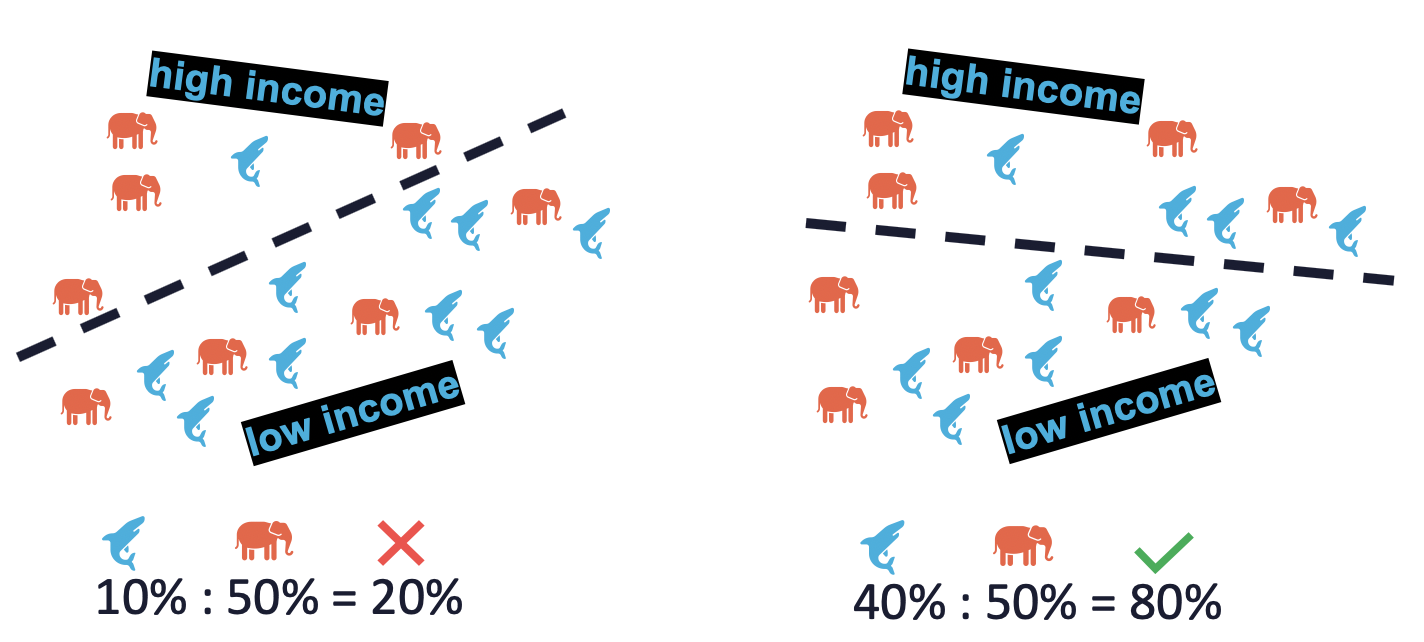
We can use the p%-rule to check if this works. This rule measures demographic parity by quantifying the disparate impact on a group of people. The p%-rule is defined as the ratio of:
An algorithm is deemed to be fair it is no less than (p%):100% — where (p%) is often set at 80%.
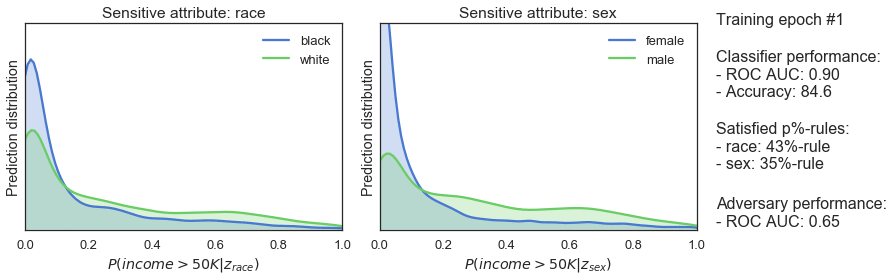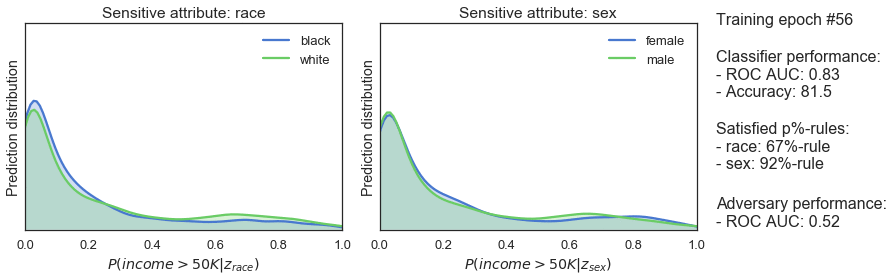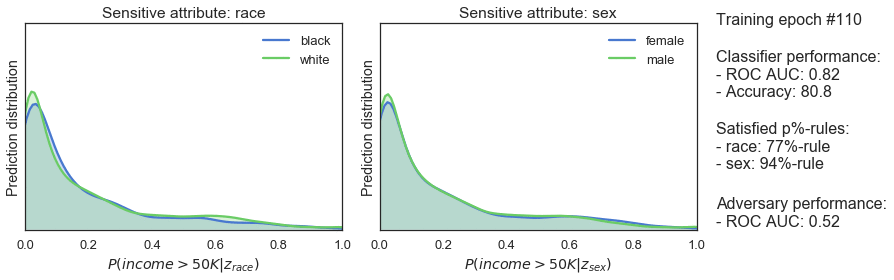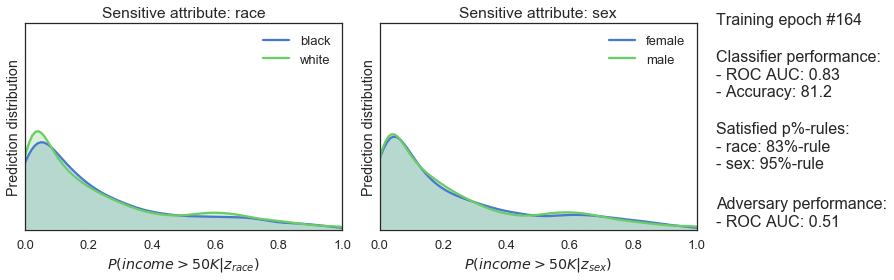
During training the classifier and adversarial take turns. The adversarial tries to predict sensitive classes from the output of the classifier and computes a unfairness penalty. During its turn, the classifier tries to get better at making predictions and being fair, enforced by a standard performance penalty and the fairness penalty. Over time, the classifier stays predictive and gets more fair – as the increasing p%-rule in the figure below show.
Being able to solve one problem is nice, but it takes a lot of effort to not end up in ML hell. Fairness in Machine Learning is not straightforward: there are many more metrics and approaches to choose from than the p%-rule and adversarial training. Training fair algorithms is also only a small piece of the puzzle: Fairness should be part of your product process. For instance, YouTube should continuously change and improve their product as new issues keep popping up. Fairness is far from being solved and needs active work!
You can find the slides of my talk at the DDSW here.
Are you interested in learning more about enforcing fairness in machine learning algorithms? GoDataDriven has two courses that will help you grasp this subject:

