Data Governance | Topics
Stop Blaming Your Data 
godatadriven 21 Dec, 2020





Berlin Buzzwords is a conference focused primarily on search, storage, streaming and scaling solutions based on open source technology. It is also focused, as its name suggests, on buzzwords: tools or techniques falling mostly in the Slope of Enlightenment phase of the Hype Cycle, with a smattering of Technology Triggers for good measure. I gave a talk this year over a tool that falls squarely in the latter category: DeepCS, a deep learning-based code search system developed by researchers at the Hong Kong University of Science and Technology and the University of Newcastle (see associated paper here).
Code search is an information retrieval problem where the query language is "natural", like English, but the target is a computer language, like Java. Traditional IR systems exist to tackle this problem by searching for, not the code, but the docstrings surrounding the code, but not every codebase is well-documented, let alone well-maintained. Even if a codebase has 100% documentation coverage that is up-to-date, these search systems still suffer from the usual IR maladies: they ignore word order, they’re not synonym-aware, and they’re easily confused by noise.
So let’s say then that at best you can treat the docstrings of the codebase as a weak search signal; how do you then go about finding relevant code snippets? Well, in principle, all that you need to know is embedded in the structure and syntax of the code itself; the problem is then finding a way to pair the code with a relevant natural language description of what that code does, in such a way that our natural-language queries can find it. DeepCS approaches this problem by simultaneously learning embeddings for both code snippets and natural-language descriptions of what those snippets do, where both embeddings live in the same vector space and querying reduces to finding the closest embedded code snippet vectors to the embedded query vector.
This blog post aims to explain their idea. We’ll assume knowledge of word embedding techniques like word2vec and basic neural network architectures; what we’ll dive into is:
Let’s assume we have a means of learning individual word embeddings, say, via word2vec; because we’ll want to convert entire queries into a single vector, we’ll need a method for aggregating the query’s component word vectors into a document vector. One approach could be to simply take the average of all the individual word vectors in the text, but it turns out that this doesn’t work the best, not in the least because the ordering of the underlying words is ignored. For instance, the phrase “cast int to string” means something very different from the phrase “cast string to int”.
A more sophisticated approach would be to use an ordering-aware machine learning model. This class of models in the deep learning field is called recurrent neural networks. These are stateful models, and when an input is passed through, not only is an output vector generated, but the internal state is updated as well. This internal state is itself just a vector, and the idea is that as you pass your inputs through one-by-one, this internal state vector remembers, in some sense, what it has already seen. (And actually, in real deep learning applications, the output vector is typically ignored; the only thing we care about is the internal state and how that changes.)
Okay, so how do we then use this hidden "memory vector" to represent our document? Well, one approach would be to simply pass the word vectors of our individual words through the recurrent neural network in the same order as their source words are found in the text, letting the hidden vector update itself over and over, and then use the final version of the hidden vector as-is once the final word vector has been passed through.
However, even though this vector in some sense "remembers" all of the words of the text, especially for long documents this vector only has a very faint memory of the first words, that is, only the last words are contributing significantly to the value of the final state of the hidden vector.

Alternatively, we could make a copy of the hidden vector after every update and combine these copies somehow. This is like the previous proposal of simply combining the individual word vectors, but now by using the hidden vectors, each vector has information not only about the individual words, but also the echoes of the words coming just before those words, and, importantly, their order.
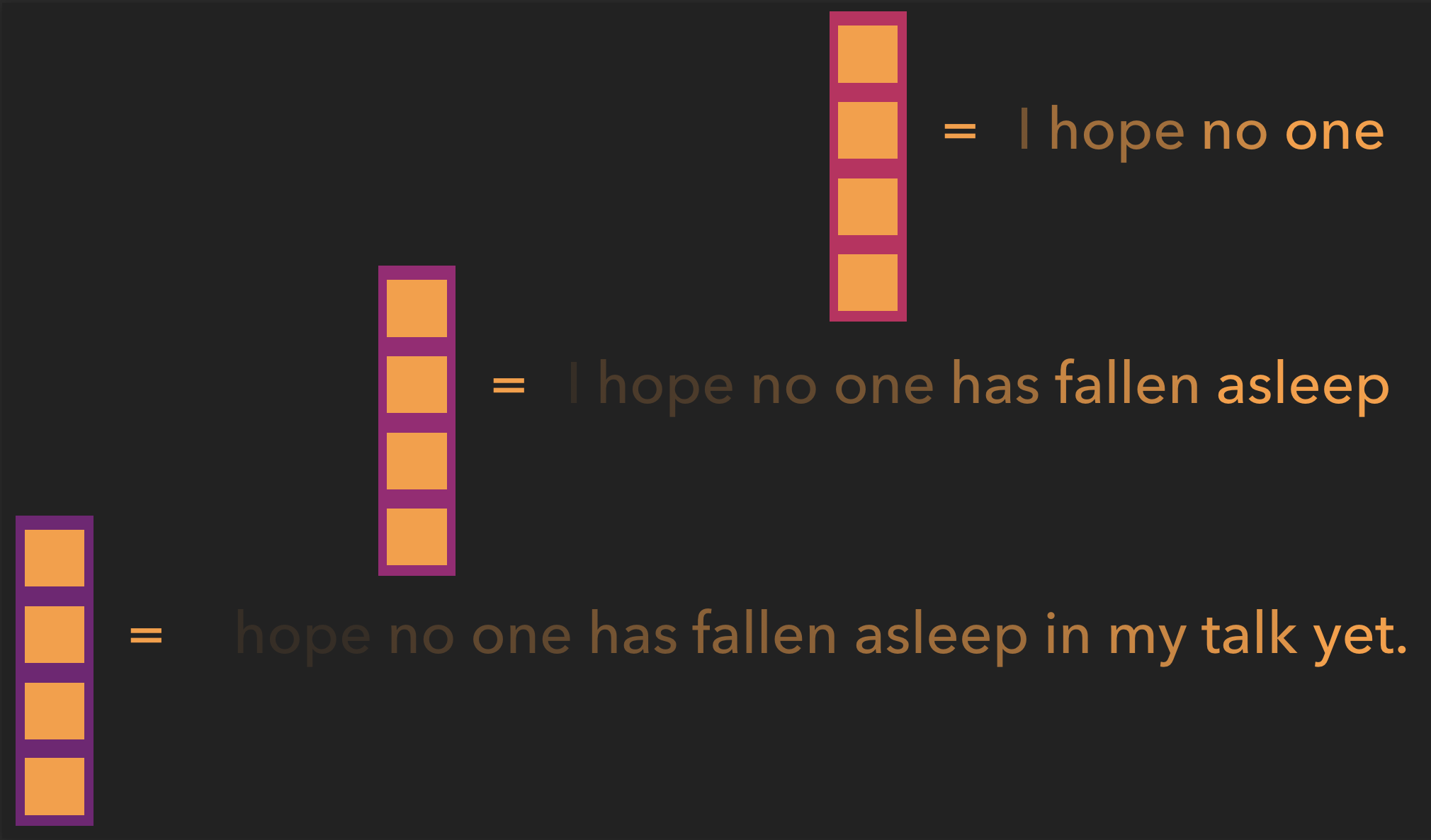
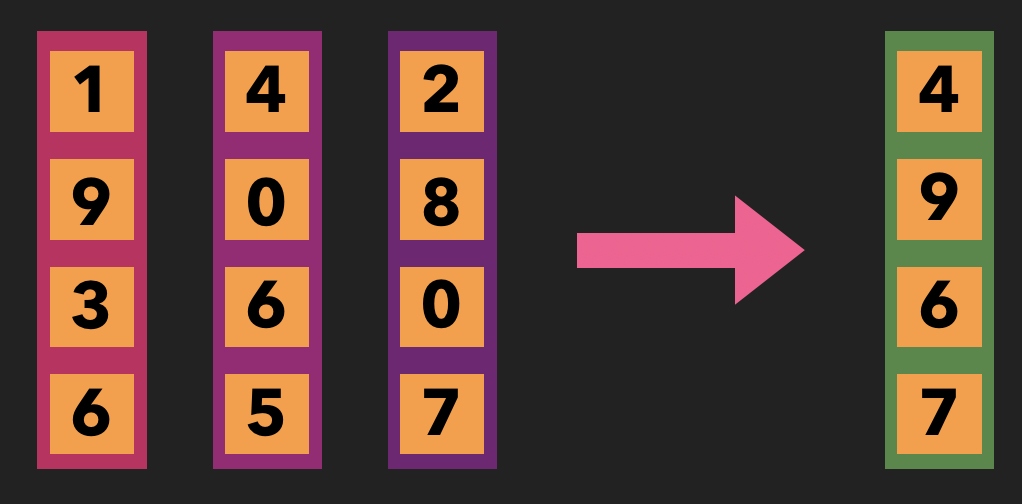
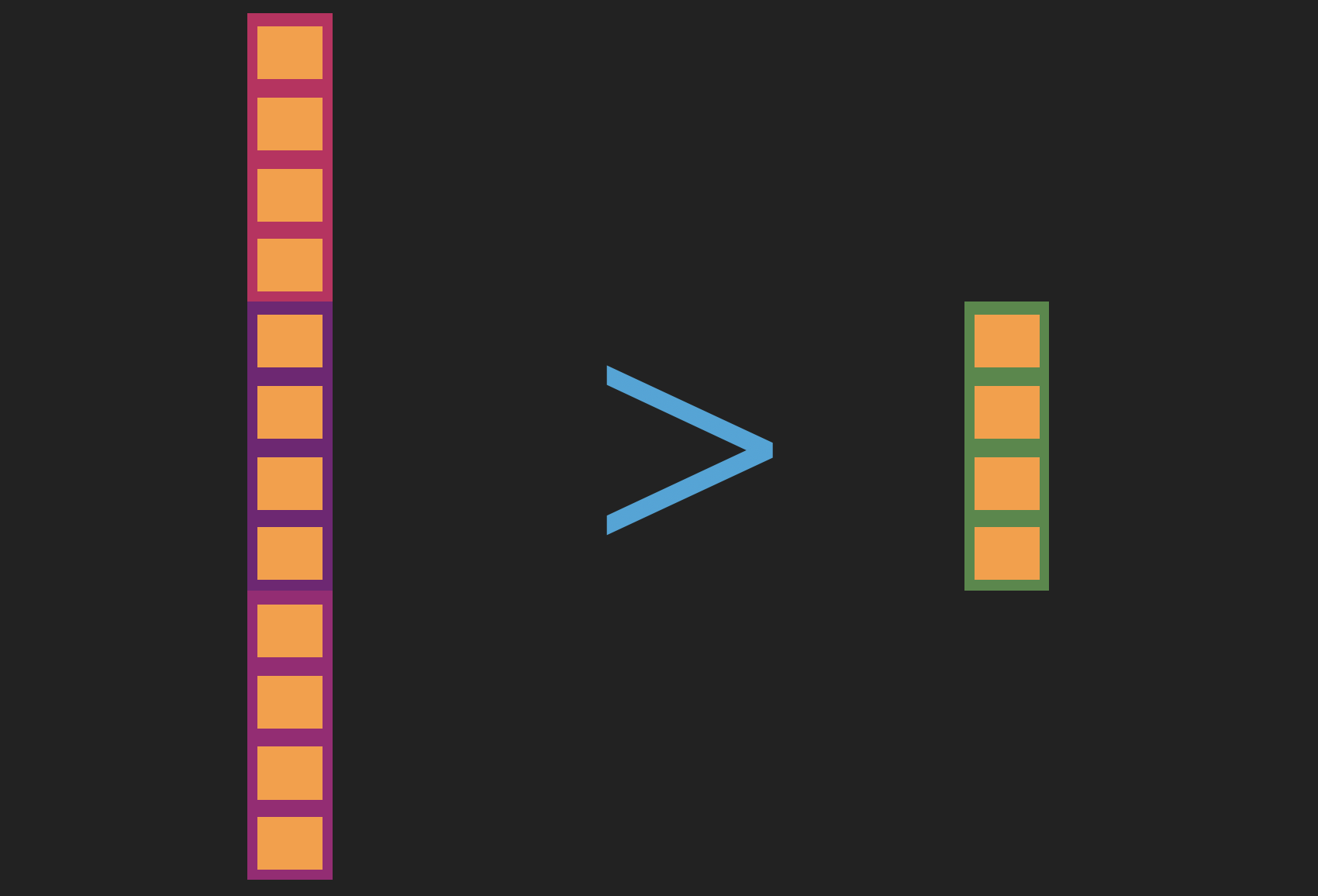
All that remains is to decide on a way of combining the hidden vectors. We might actually be able to get away with simply averaging them, just as we proposed to do for the word vectors, but the authors of the paper did something different, called max pooling: what you do is make a new vector the same size as all of our hidden vectors, and set the value for each component equal to the maximum for all the values for that component across all hidden vectors.
Having seen how to make a small-dimensional representation of textual documents, we’d like to do something similar with our code snippet. However, there are a few things we need to keep in mind. (This post will refer to Java as an example, but the paper’s authors assert the choice of language doesn’t matter to the technique.)
First of all, on the surface, the variable and class names we use are themselves text, but unlike in most natural languages there’s no implied requirement that the word used directly relates to the action being performed or to the role of the object.
On the other hand, despite how we choose to name things, the underlying API calls and control flows are completely unambiguous, and noticing that these calls are ordered, and that there’s only a finite number of possibilities, we realize that we can build a dictionary of the API calls and train a small-dimensional embedding of them much like what did with word2vec.
To do so, we start with some large collection of code snippets, and for each we generate and traverse its abstract syntax tree, collecting an ordered sequence of API calls. For instance, for each constructor invocation new Foo(), we append to our sequence the API Foo.new, or for each method call o.bar() where o is an instance of class Foo, we append the API call Foo.bar. And for loops and other control logic, we can append the constituent API calls in some deterministic way.
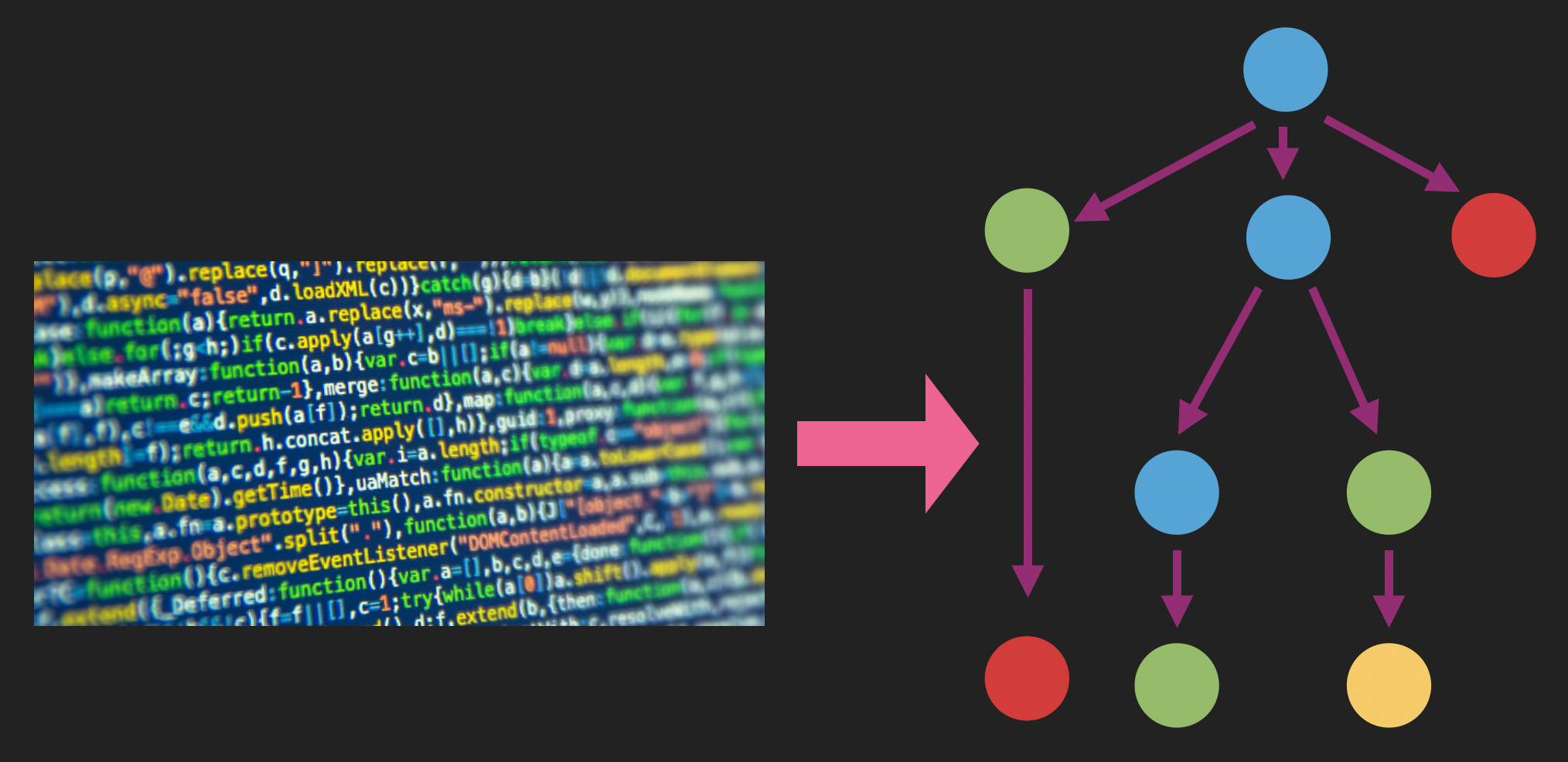
We then look at all the sequences of all our code snippets, make a dictionary of all the API calls we find, and assign a one-hot encoding to each API call. We then train a word2vec-like model to predict, for a given one-hot encoding of an API call in a particular sequence, the one-hot encoding of its neighboring API calls in that sequence. And just like in the text case, this results in a small-dimensional representation of each API call.
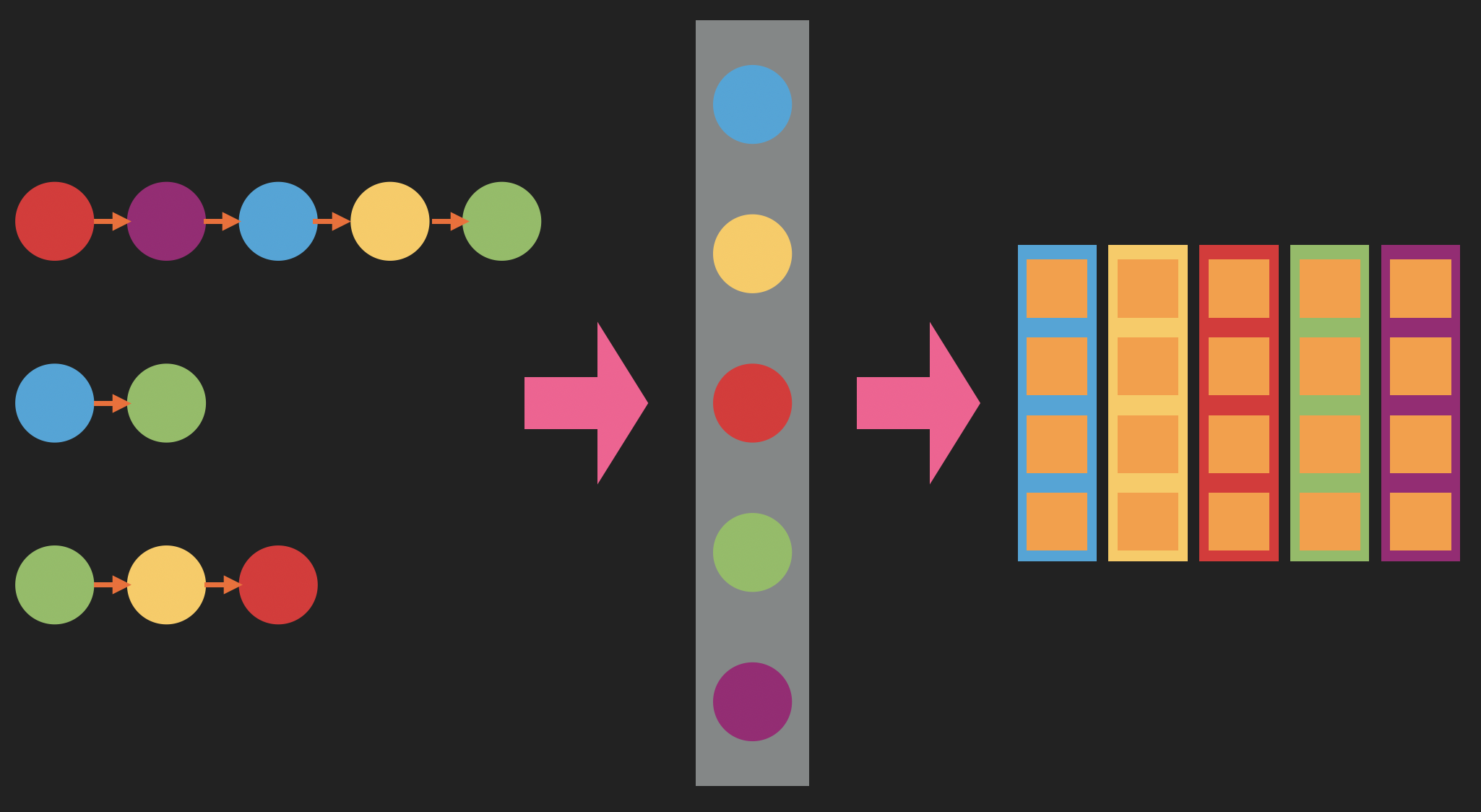
Lastly, to obtain a representation of the API sequence of each code snippet, we then pass these vectors, in order, through a recurrent neural network (a different one than that which we use for the text but having the same architecture), collect the generated hidden vectors, and aggregate them via max pooling.
Of course, there’s some flexibility in the order and choice of the API calls and how we structure the control logic, and so this is also not completely sufficient to represent the intent behind the code snippet in a general way. To achieve that, what the team behind DeepCS did was to combine the API sequence embedding with the weak signals originating from the text of the code snippet.
First, we create a representation of the method name. By splitting the method name into its constituent tokens, we have words and word order, and so we can apply the word2vec techniques we’re by now familiar with, along with a third recurrent neural network, to generate an embedding vector.
Secondly, just to ensure we don’t miss any potential signals, we take the method body, split all variable and method names into their constituent words, apply the familiar bag-of-words tricks we know from information retrieval like deduplication, natural language stop word removal, and code language stop word removal (that is, removing all language keywords), and embed the remaining words in small-dimensional vectors. We don’t pass these vectors through an RNN, though, since unlike the method name words and API calls they have no strict ordering, so instead we put them through a normal feedforward neural network and maxpool the resulting vectors.
As a concrete example, here’s a simple example for a method that converts a Date into a Calendar (taken from the original paper):
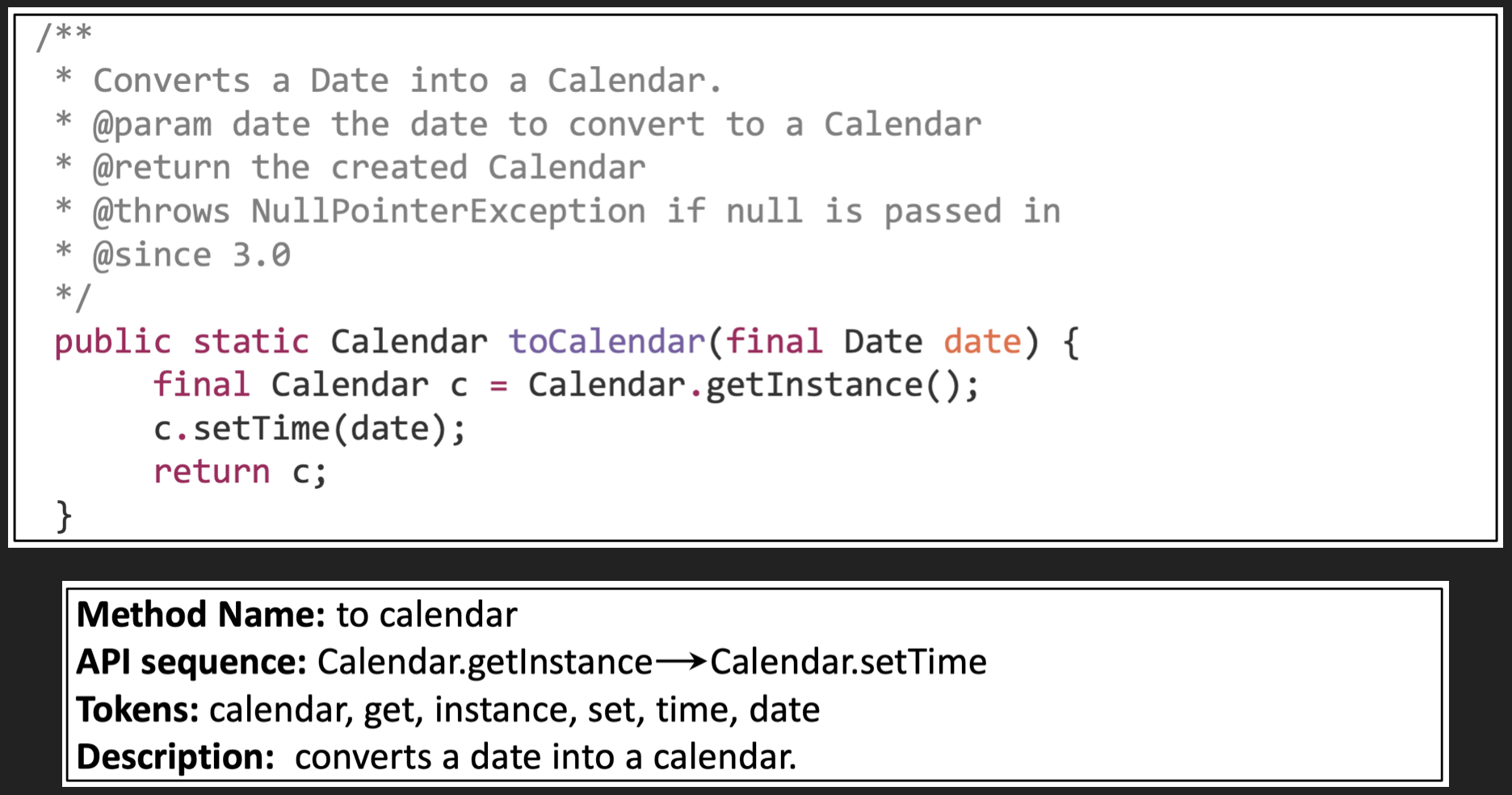
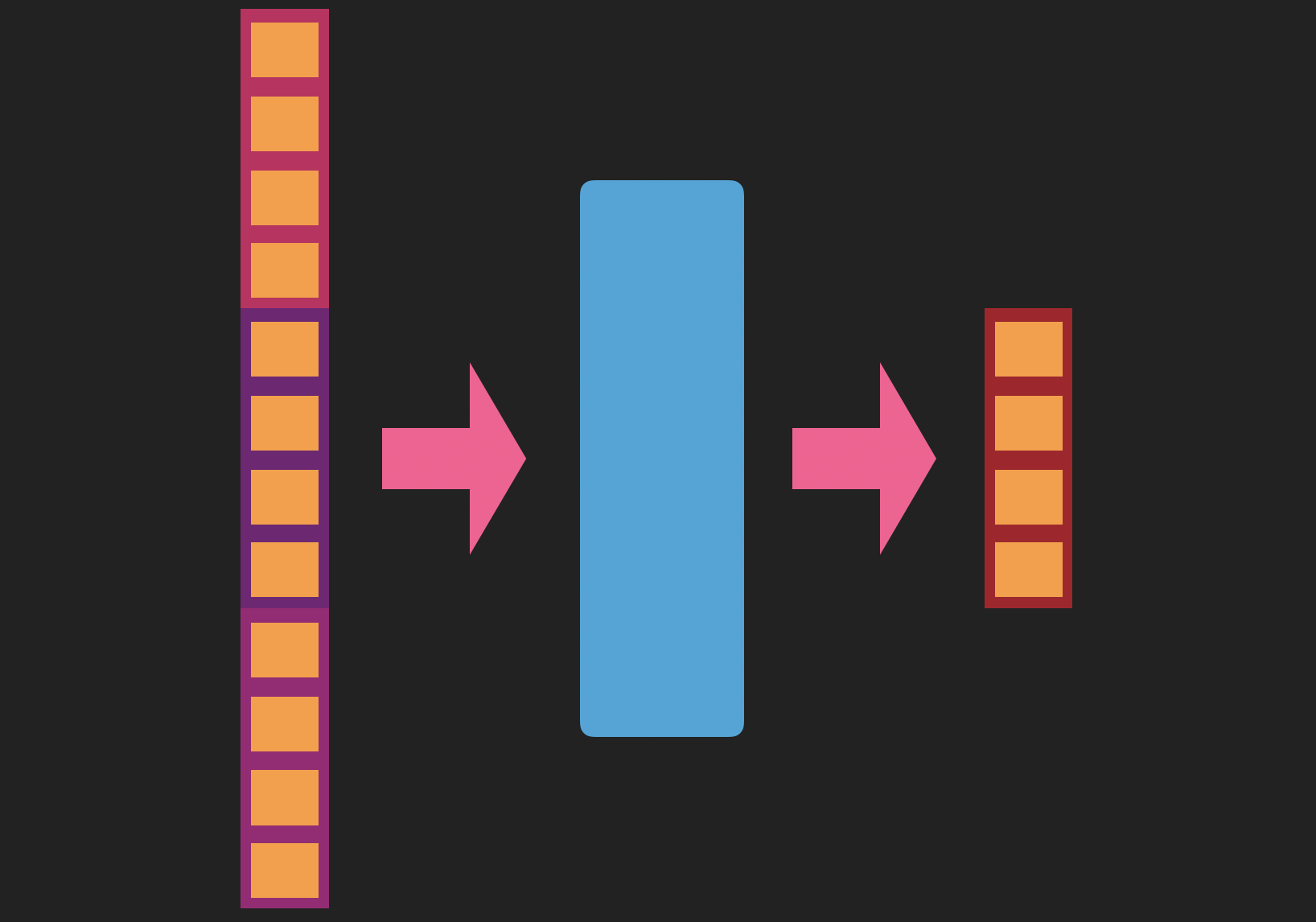
Calendar.getInstance and Calendar.setTime have been extractedfinal and return.This process leaves us with three separate vectors representing all the signals we can squeeze out from a method definition. Together, though, they have more dimensions than the text vectors we’ll use to represent queries, as the method name alone has this many dimensions. Since we want to be able to compare the two vectors, they’ll have to have the same length, and so simply concatenating the vectors derived from the code method won’t work.
Instead, as a final step, we concatenate the three and put them through a feedforward neural network, whose output layer is the same size as a text vector. In addition to resulting in a vector of the appropriate size, as an added benefit this last transformation will also learn to mix the individual signals coming from the method name, API calls and method tokens in the most illuminating way.
So, now we have methods both for creating vectors from text and for creating vectors from code; how do we learn these transformations in such a way that vectors representing text describing some action are close or equal to vectors representing code that performs that action?
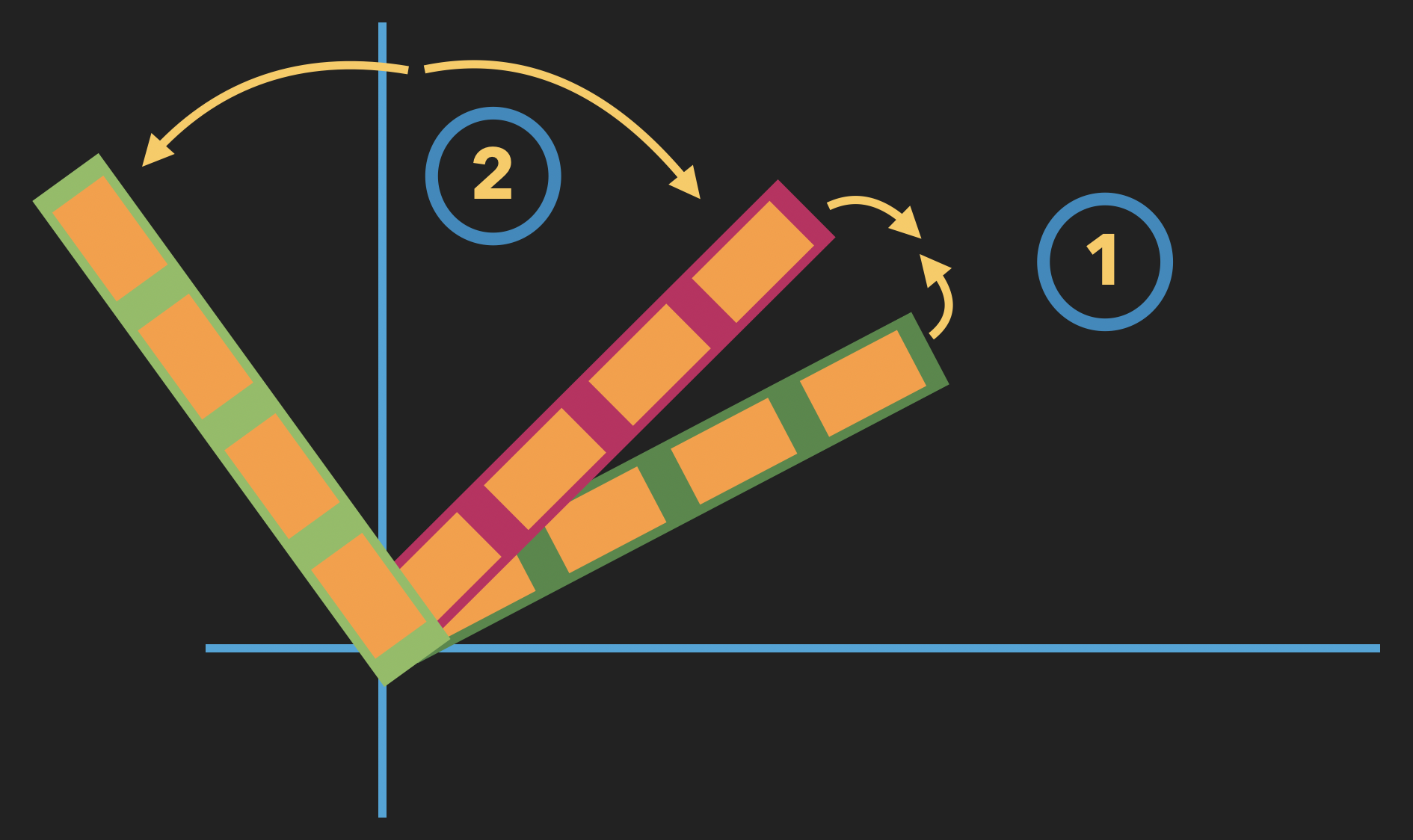
Now, normally, training a machine learning model works by providing the model with an input and target output to predict based on that input. But in the embedding case, we don’t have a target output for either the natural language transformation model, nor the code transformation model. Instead, our "target" is that the vector for a piece of text describing an action, and the vector embedding the code actually performing that action, be close to one another, if not overlapping. To achieve this, we use a technique what’s called a joint embedding, where instead of looking at the output of the natural language and code transformations separately, we compare their output vectors and seek to minimize the angle between them.
Additionally, just like using negative sampling in word2vec, it turns out that this training procedure works even better if we simultaneously also seek to maximize the angle between the code snippet’s vector and the vector of some action description that has nothing to do with the action the code performs.
So it’s by optimizing for this combined goal that we simultaneously train our two embeddings, and this joint model is what the authors of the paper call the Code-Description Embedding Neural Network, or CODEnn.
As a demonstration of the feasibility of this idea, the team behind CODEnn developed a system for code search called DeepCS. This system works in three phases.
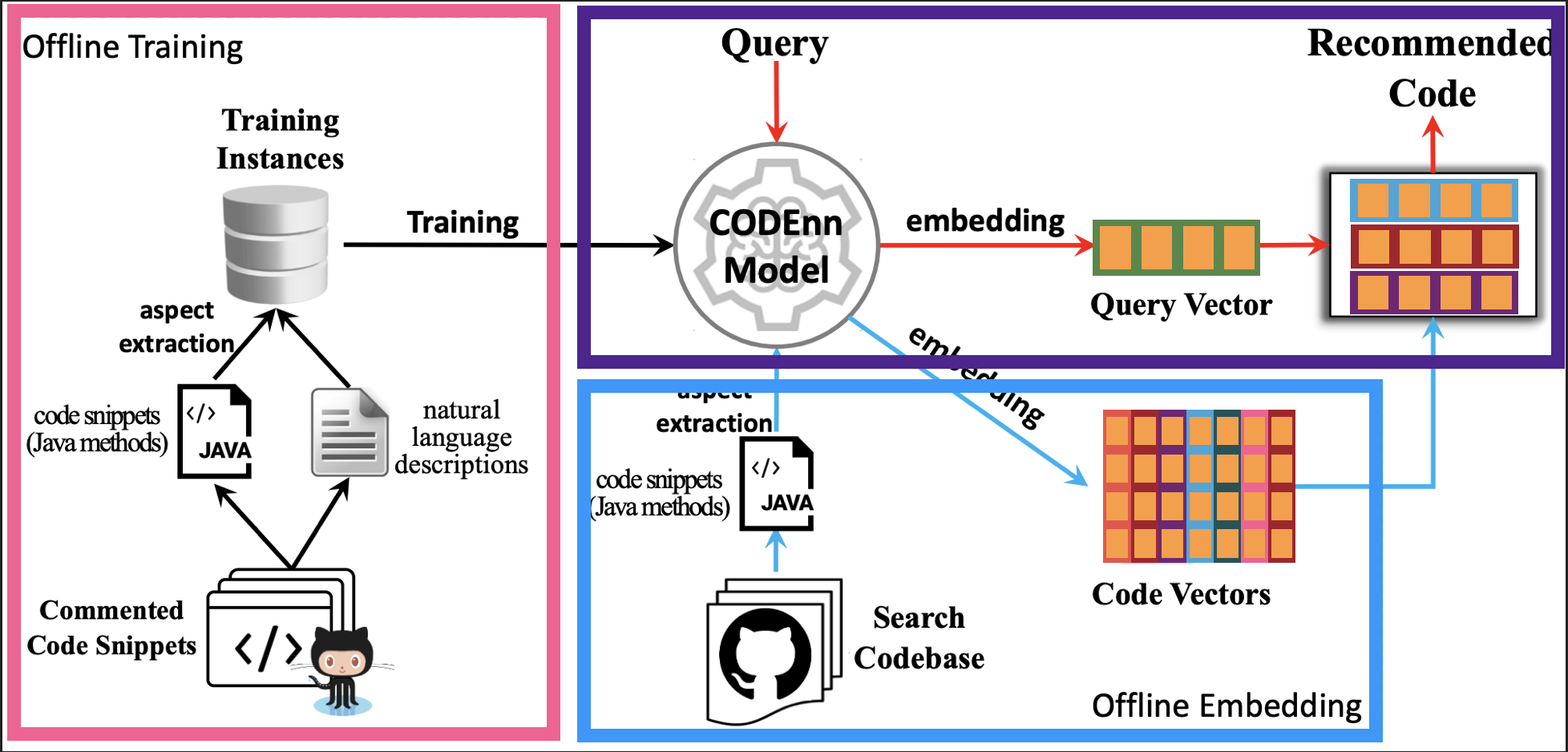
The first uses 18 million Java methods and their associated docstrings, all scraped from GitHub, to train both the code and natual language embeddings. This is done once; the code and docstrings are then discarded and only the learned transformations retained. This training dataset is purposely quite broad in order to guarantee that the representations learned will also be useful for as-yet-unseen codebases, that is to say, yours.
Next, you throw all of the code snippets from your code base, without docstrings, into the system, and the previously-learned transformations are used to convert all of these methods into vectors. This is also done once, but you can imagine a situation where code that was touched during the day has its vector representation recalculated at night.
Notice too that this is a relatively cheap operation, relative to the training required to learn the transformations.
Lastly, now that DeepCS is ready for search, when a user of the system wants to find a relevant piece of code, he or she enters their natural-language query into the system. DeepCS transforms the textual query into a vector, performs a search to find the K-nearest code vectors to our natural language query vector, and returns the corresponding code snippets to the user in decreasing order of proximity.
When I delivered a talk about using machine learning to build database indexes at Berlin Buzzwords last year, machine learning talks were few and far between (and often when given were about learning-to-rank), not surprising given the hard error guarantees demanded by database systems. This year it seemed like the buzzword was machine learning, and in particular it seemed like word embeddings were considered prerequisite knowledge. Keep your eyes open for more deep learning-based information retrieval systems at the conference next year, and their affiliated buzzword: Search 2.0.
Join us for our three-day Deep Learning course, where you will learn everything about what it takes to apply deep learning in your job.


