Uncategorized
QCon San Francisco 2008 - Impressions 
Age Mooij 25 Nov, 2008





![]()
GoDataDriven is helping the NS (Dutch Railways) in becoming a data driven organization. In particular, we are collecting the sensor measurements coming from the train fleet continuously in large amounts and at rapid pace. Think about speed and location of the train; temperature, voltage and pressure of mechanical components; aggregated diagnose messages; state changes; etcetera.
At this time of writing, we are approaching the staggering amount of 100 billion sensor measurements.
This is all fine and dandy, but of course the important question is what to do with the data in order to create value for the NS. For this, the people at the ‘Maintenance Development’ department are conducting research to using sensor data for predicitve maintenance – one of the key application areas of machine learning.
Among them is Wan-Jui Lee. After obtaining her PhD in electrical engineering in Taiwan and fulfilling several R&D positions in science and industry, she decided to join the NS and help developing predictive maintenance solutions.
In particular, she developed a method for early detection of air leakage in the train braking pipes. A functioning braking system is of course a required condition for the train to operate, thus being able to detect such a failure and replace or fix the pipe or compressor on exactly the right moment is of crucial importance. This saves the costs associated to premature or overdue replacement – let alone the damage done to the passengers. Moreover, air leakage is notoriously difficult to detect in noisy maintenance workplaces, which renders the automation thereof as highly useful.
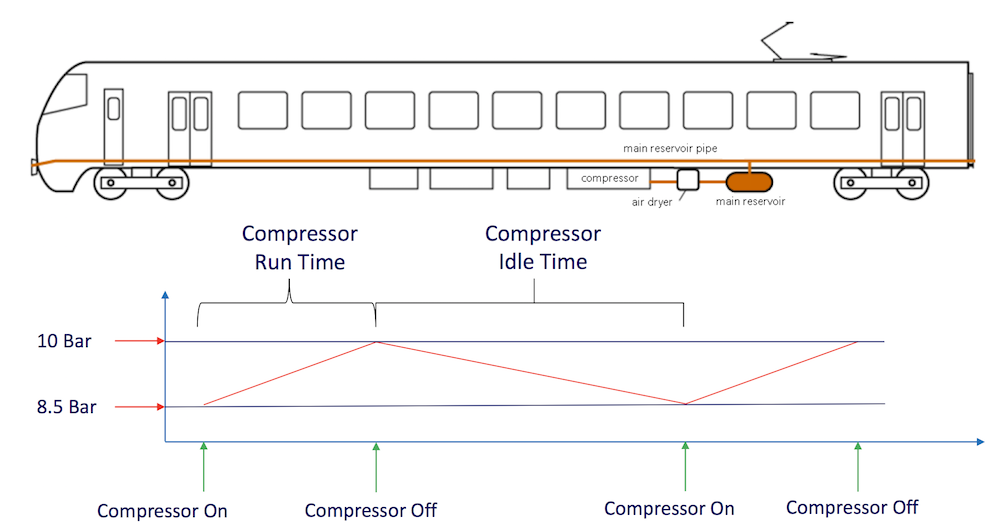
The detection method developed by Wan-Jui involves a sequence of relatively straightforward statistical models based on the compressor logs – i.e. timestamps of the compressor switching on or off. After all, when the compressor switches on more frequently, that might be due to an air leakage.
Based on real time monitoring of compressor behaviour, air leakage can typically be detected 2 to 3 weeks before total failure and therefore leaves sufficient room for operational handling.
The work has been published in the International Journal of Prognostics and Health Management in 2017.
![]()
In order to operationalize the research of Wan-Jui, the method must be implemented in such a way that the huge amounts of sensor data that are collected every day can be used to build the predictive models. This is where GoDataDriven comes in: we bring the knowledge and skills to implement the method in Python (or Scala, depending on the data science/engineering role;), and to use Spark as the processing engine for dealing with the large and distributed dataset stored on Hadoop.
We implemented the method such that new models can be trained every night for every train, using the latest measurements. For this, our own Ivo Everts teamed up with Cyriana Roelofs and Mattijs Suurland from the ‘Data & Analytics’ department. The implementation is ready, and we are now entering the phase in which the algorithmic results will be tested in an operational setting. That is, we connect to the maintenance engineers at the workplace and steer them to carefully inspect the braking pipes in which air leakage has been detected.

This work makes for a crisp and clear case in which the power of machine learning at scale is demonstrated in an industrial setting. Spark is an excellent choice for this, as it provides a convenient programmatic interface to huge datasets, and comes with off-the-shelve implementations of a wide range of standard machine learning algorithms.
Considering the fact that AI is the newest buzzword (it’s actually a superset of machine learning), it figures that our work makes for a nice session at the next Spark+AI summit in San Francisco, early June.
See you there!?


