Data | Domains
Masterclass "Real-world machine learning" at UVA 
Walter van der Scheer 11 Apr, 2016





In this blog post I provide an overview of a Python skeleton application I made. This skeleton can help you bridge the gap between your model and a machine learning application.
For example, you can use your existing Flask application, import it in run_app.py as app, and this will add the production ready features of Gunicorn.
The times when business saw machine learning models as black boxes with no hope of understanding are long gone.
It use to be that the data analytics or data science department of a company produced results in a silo kind of environment. Little or no interaction took place between these departments and the business side making the decisions (marketing, sales, client support, etc.). Advice coming from machine learning models consisted of reports, which were nice to have if they supported ideas from the business.

As data driven decisions demonstrated their value, the business side started peeking behind the curtain.
Paper/files reports have been substituted by static reporting dashboards, which themselves are being replaced by interactive ones. The business end users want to interact with the models, understand why certain predictions are made and evenmore, they want to be capable of performing predictions on the fly (imagine simultaneously having a customer on the phone and updating the probabilities of him/her buying certain products, or a marketing department tuning campaigns themselves depending on regional features).
In short, I had some time during a rainy weekend and a GDD Friday1, already did something similar for a client and I think it is important to bring machine learning models to the business side.
Also, as a bonus they will stop bothering you every time they need insights or a slightly different prediction.
This allows the application to be run in a more production ready environment (multiple workers and threads for example). In here you can find a complete list of all the possible Gunicorn settings. I added the possibility to use some of them as command line arguments. Some relevant ones are:
hostportworkers – define number of workers.threads – number of threads on each worker.daemon – run application in the background.access-logfile – save access logs to a file.forwarded-allow-ips – list allowed IP addresses.

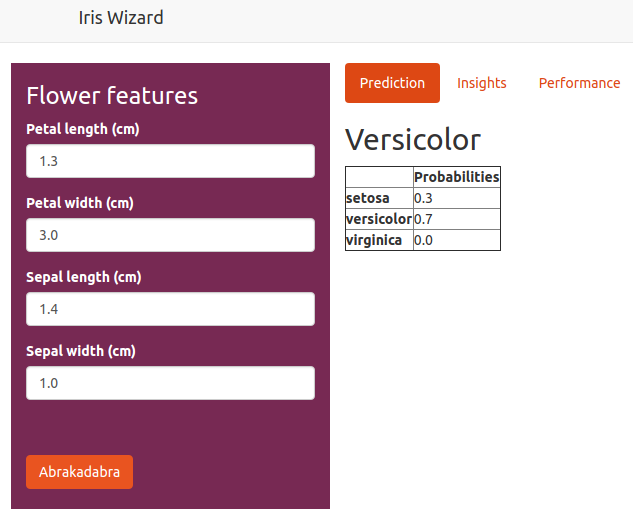
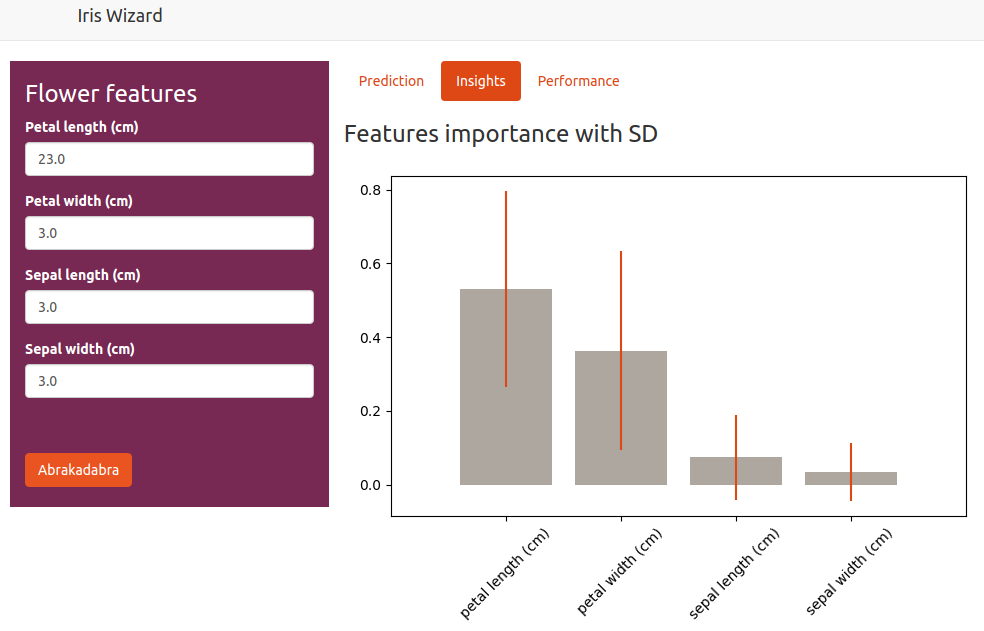
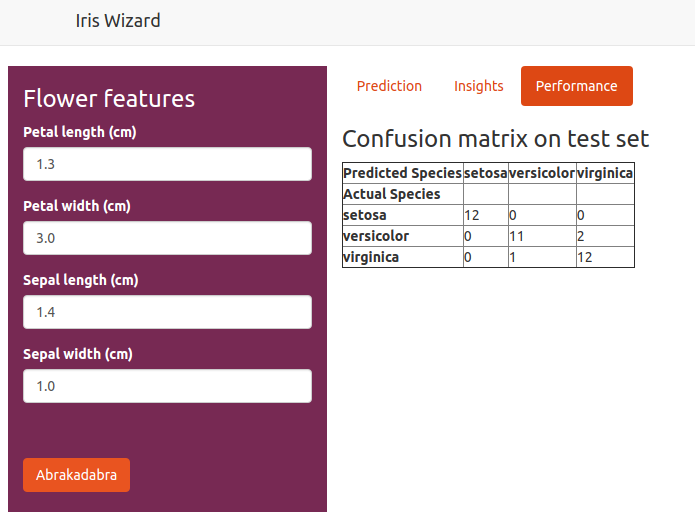
The model can be run by using the UI or by directly making a post request to the endpoint.
A more complete description, a set of instructions and the code can be found in this repository.
Note: I also include a setup.py file that you should use to install your package used in the application.
If you structure your project following the advice from Henk Griffioen (A.K.A. El Chicano), the integration of this ML application skeleton to your project should be straight forward.
I hope this work can help you bring your models into a machine learning application, it certainly helped and will help me in the future. You can find the code here.
At GoDataDriven we offer a host of Python courses taught by the very best professionals in the field. Join us and level up your Python game:


