Data | Domains
Retrospect on Spark Summit 2016 
Walter van der Scheer 04 Nov, 2016





This document contains a tutorial on how to provision a spark cluster with Rstudio. You will need a machine that can run bash scripts and a functioning account on AWS. Note that this tutorial is meant for Spark 1.4.0. Future versions will most likely be provisioned in another way but this should be good enough to help you get started. At the end of this tutorial you will have a fully provisioned spark cluster that allows you to handle simple dataframe operations on gigabytes of data within RStudio.
Make sure you have an AWS account with billing. Next make sure that you have downloaded your .pem files and that you have your keys ready.
Next go and get spark locally on your machine from the spark homepage. It’s a pretty big blob. Unzip it once it is downloaded go to the ec2 folder in the spark folder. Run the following command from the command line.
./spark-ec2 --key-pair=spark-df --identity-file=/Users/code/Downloads/spark-df.pem --region=eu-west-1 -s 1 --instance-type c3.2xlarge launch mysparkr
This script will use your keys to connect to amazon and setup a spark standalone cluster for you. You can specify what type of machines you want to use as well as how many and where on amazon. You will only need to wait until everything is installed, which can take up to 10 minutes. More info can be found here.
When the command signals that it is done, you can ssh into your machine via the command line.
./spark-ec2 -k spark-df -i /Users/code/Downloads/spark-df.pem --region=eu-west-1 login mysparkr
Once you are in your amazon machine you can immediately run SparkR from the terminal.
chmod u+w /root/spark/ ./spark/bin/sparkR
As just a toy example. You should be able to confirm that the following code already works.
ddf createDataFrame(sqlContext, faithful)
head(ddf)
printSchema(ddf)
This ddf dataframe is no ordinary dataframe object. It is a distributed dataframe, one that can be distributed across a network of workers such that we could query it for parallized commands through spark.
This R command you have just run launches a spark job. Spark has a webui so you can keep track of the cluster. To visit the web-ui, first confirm on what IP-adres the master node is via this command:
curl icanhazip.com
You can now visit the webui via your browser.
:4040
From here you can view anything you may want to know about your spark clusters (like executor status, job process and even a DAG visualisation).
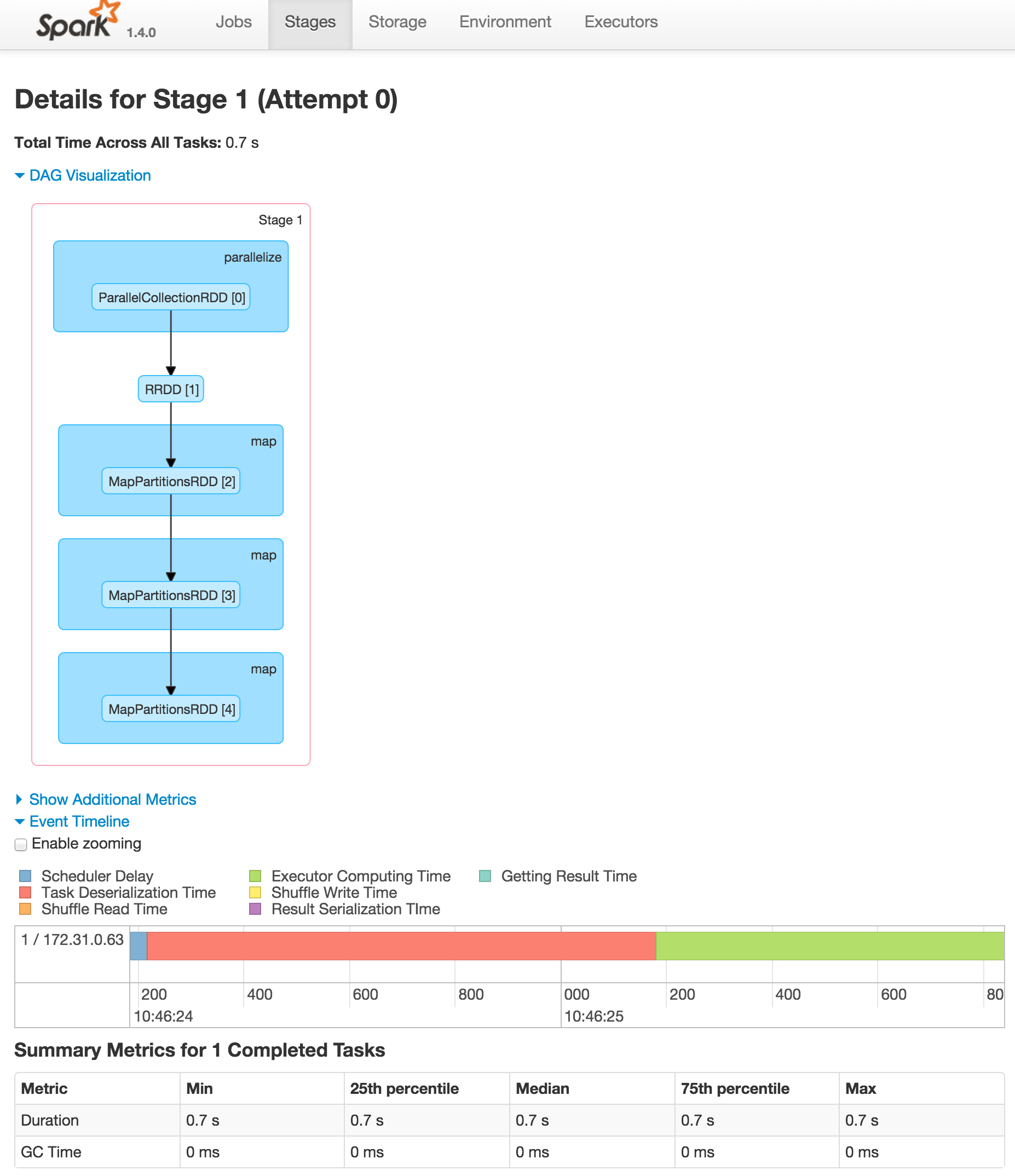
This is good moment to stand still and realize that this on it’s own right is already very cool. We can start up a spark cluster in 15 minutes and use R to control it. We can specify how many servers we need by only changing a number on the command line and without any real developer effort we gain access to all this parallizing power.
Still, working from a terminal might not be too productive. We’d prefer to work with a GUI and we would like some basic plotting functionality when working with data. So let’s install Rstudio and get some tools connected.
Get out of the SparkR shell by entering q(). Next, download and install Rstudio.
wget http://download2.rstudio.org/rstudio-server-rhel-0.99.446-x86_64.rpm sudo yum install --nogpgcheck -y rstudio-server-rhel-0.99.446-x86_64.rpm rstudio-server restart
While this is installing. Make sure the TCP connection on the 8787 port is open in the AWS security group setting for the master node. A recommended setting is to only allow access from your ip.

Then, add a user that can access rstudio. We make sure that this user can also access all the rstudio files.
adduser analyst passwd analyst
You also need to do this (the details of why are a bit involved). These edits need to be made because the analyst user doesn’t have root permissions.
chmod a+w /mnt/spark chmod a+w /mnt2/spark sed -e 's/^ulimit/#ulimit/g' /root/spark/conf/spark-env.sh > /root/spark/conf/spark-env2.sh mv /root/spark/conf/spark-env2.sh /root/spark/conf/spark-env.sh ulimit -n 1000000
When this is known, point the browser to <master-ip-adr>:8787. Then login in as analyst.
Awesome. Rstudio is set up. First start up the master submit.
/root/spark/sbin/stop-all.sh /root/spark/sbin/start-all.sh
This will reboot Spark (both the master and slave nodes). You can confirm that spark works after this command by pointing the browser to <ip-adr>:8080.
Next, let’s go and start Spark from RStudio. Start a new R script, and run the following code:
print('Now connecting to Spark for you.') spark_link system('cat /root/spark-ec2/cluster-url', intern=TRUE) .libPaths(c(.libPaths(), '/root/spark/R/lib')) Sys.setenv(SPARK_HOME = '/root/spark') Sys.setenv(PATH = paste(Sys.getenv(c('PATH')), '/root/spark/bin', sep=':')) library(SparkR) sc sparkR.init(spark_link) sqlContext sparkRSQL.init(sc) print('Spark Context available as "sc". \n') print('Spark SQL Context available as "sqlContext". \n')
Let’s confirm that we can now play with the Rstudio stack by downloading some libraries and having it run against a data that lives on S3.
small_file = "s3n://: dist_df read.df(sqlContext, small_file, "json") %>% cache@ /data.json"
This dist_df is now a distributed dataframe, which has a different api than the normal R dataframe but is similar to dplyr.
head(summarize(groupBy(dist_df, df$type), count = n(df$auc)))
Also, we can install magnittr to make our code look a lot nicer.
local_df dist_df %>%
groupBy(df$type) %>%
summarize(count = n(df$id)) %>%
collect
The collect method pulls the distributed dataframe back in to a single machine so you can use plotting methods on it again and use R. A common usecase would be to use spark to sample or aggregate a large dataset which can then be further explored in R.
Again, if you want to view the spark ui for these jobs you can just go to:
:4040
Unfortunately this stack has an old version of R (we need version 3.2 to get the newest version of ggplot2/dplyr). Also, as of right now there isn’t support for the machine learning libraries yet. These are known issues at the moment and version 1.5 should show some fixes. Version 1.5 will also feature rstudio installation as part of the ec2 stack.
Another issue is that the namespace of dplyr currently conflicts with sparkr, time will tell how this gets resolved. Same would go for other data features like windowing function and more elaborate data types.
When you are done with the cluster. You only need to exit the ssh connection and run the following command:
./spark-ec2 -k spark-df -i /Users/code/Downloads/spark-df.pem --region=eu-west-1 destroy mysparkr
The economics of spark are very interesting. We only pay amazon for the time that we are using Spark as a compute engine all other times we’d only pay for S3. This means that if we analyse for 8 hours, we’d only pay for 8 hours. Spark is also very flexible in that it allows us to continue coding in R (or python or scala) without having to learn multiple domain specific languages or frameworks like in hadoop. Spark makes big data really simple again.
This document is meant to help you get started with Spark and Rstudio but in a production environment there are a few things you still need to account for:
Spark is an amazing tool, expect more features in the future.
It can happen that the ec2 script hangs in the Waiting for cluster to enter 'ssh-ready' state part. This can happen if you use amazon a lot. To prevent this you may want to remove some lines in ~/.ssh/known_hosts. More info here. Another option is to add the following lines to your ~/.ssh/config file.
# AWS EC2 public hostnames (changing IPs) Host *.compute.amazonaws.com StrictHostKeyChecking no UserKnownHostsFile /dev/null
