Data | Domains
Neo4j HA on a Raspberry pi cluster 
GoDataDriven 18 Apr, 2016





In this blog we will describe how we performed the upgrade of the Hadoop cluster to the new version of the Cloudera Hadoop distributions. Although this upgrade is well documented by Cloudera the upgrade was not without a fight. We will explain the problems and the solutions.
The reason to upgrade the cluster has multiple advantages:
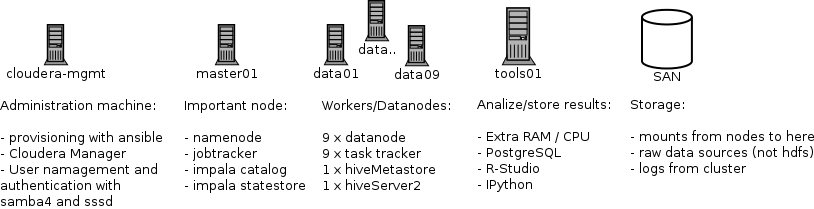
The cluster exists of 13 physical machines running CentOS 6 with a SAN (big harddrive) for the raw data and collecting logs form the cluster.
On all machines we have root access and all command are being executed as root. All machines have Java 1.6 with the Java Extended Crypo Policy in place, which is required for a Kerberos secured cluster. We did not ‘yum update’ all the machines before the upgrade.
In the cluster we have these nodes:
Before the upgrade the cluster was using the parcels:
We were using the following services:
Cloudera has a very good and complete documentation. To upgrade we followed the cloudera-CDH5-upgrade-guide.
During this step the cluster is still available for usage.
The following steps are described in cloudera-manager-upgrade-guide.
node: cloudera-mgmt:
$ service cloudera-scm-server stop
$ service cloudera-scm-server-db stop
$ service cloudera-scm-agent stop
wget http://archive.cloudera.com/cm5/redhat/6/x86_64/cm/cloudera-manager.repo
mv cloudera-manager.repo /etc/yum.repos.d/
yum clean all
yum upgrade 'cloudera-*'
rpm -qa 'cloudera-manager-*'
should look like:
cloudera-manager-server-5.0.2-1.cm502.p0.297.el6.x86_64
cloudera-manager-daemons-5.0.2-1.cm502.p0.297.el6.x86_64
cloudera-manager-server-db-2-5.0.2-1.cm502.p0.297.el6.x86_64
sudo service cloudera-scm-server-db start
sudo service cloudera-scm-server start
less /var/log/cloudera-scm-server/clou*.log
The installation of Cloudera Manager 5 was done without any problems, yej!
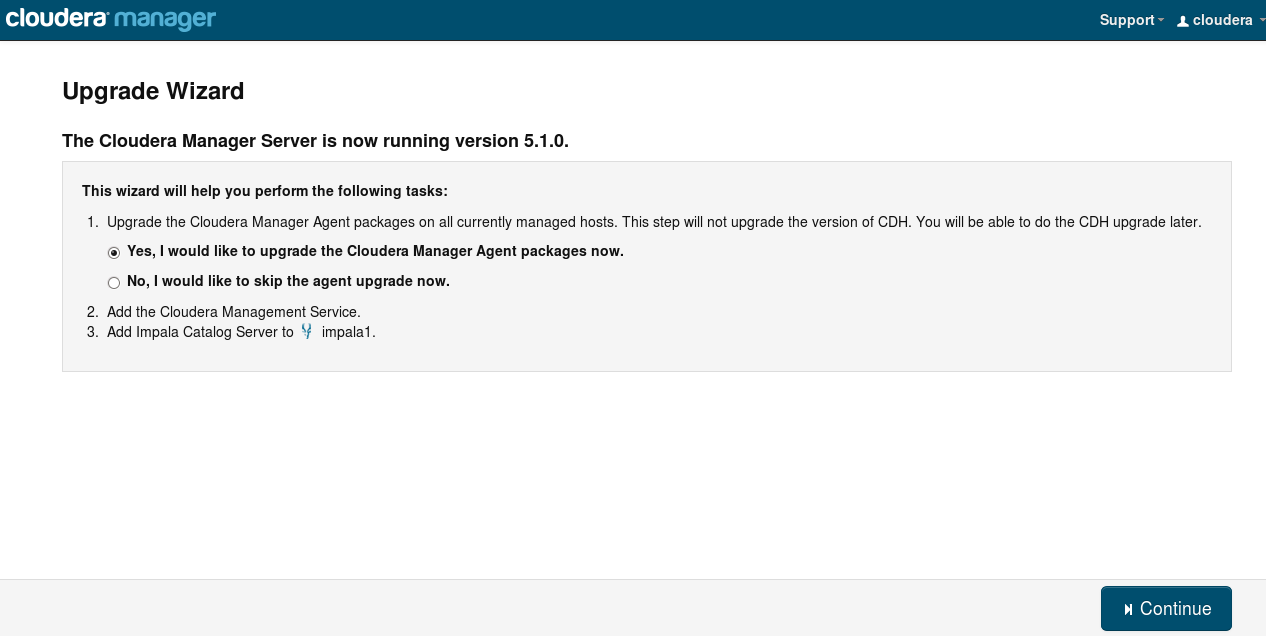
After the loggin in the Cloudera Manager it will suggest to upgrade the agents.
Following the upgrade cluster wizard. (the screenshots are taken from other upgrade to 5.1.0, but are very similar)
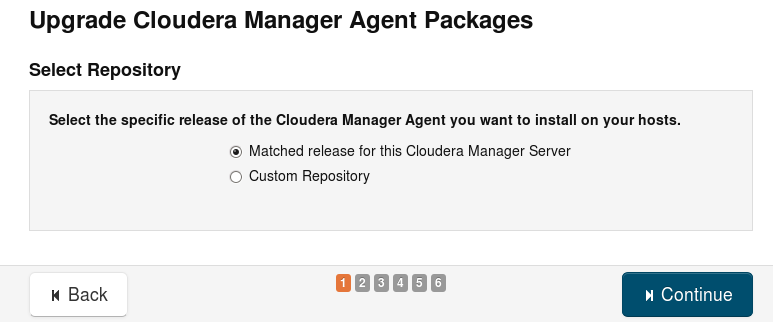
When the cluster is not connected to internet, you must download the parcels and serve them yourself. Then you must use the Custom Repository pointing to that location which serves the manifest.json and parcel files.
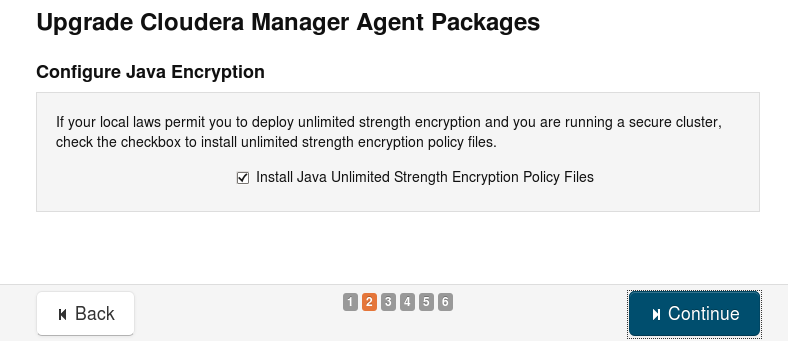
This is required for Kerberos security. This policy is specific for the rolled out version (Java 1.7), if you have installed 1.7 before you should still check the box for the new java version.
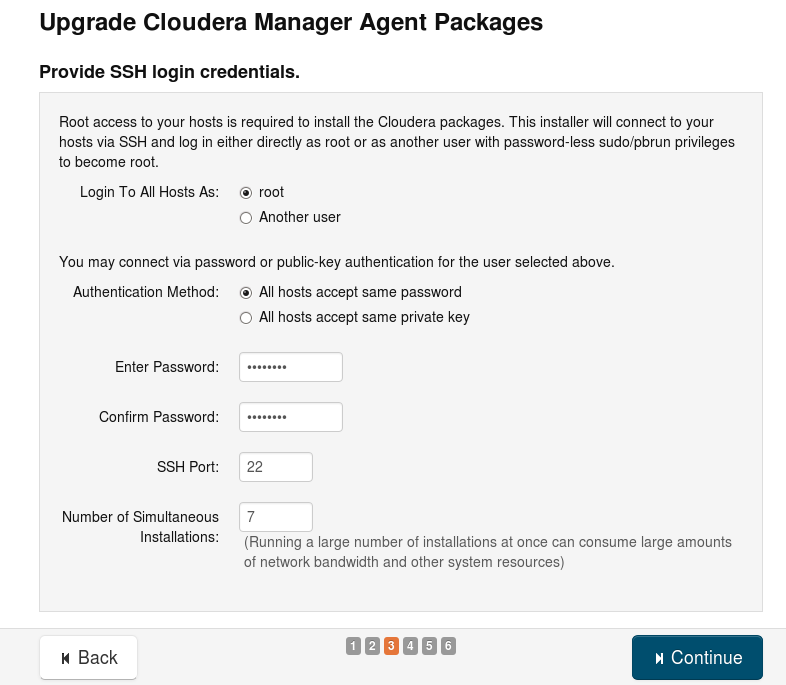
How Cloudera Manager connect to the agents is defined here. The number of simultaneous installations is a number to think about.
Try to pick a ‘smart’ number, we have 12 nodes that are being upgraded. We used the default 10 and and it took a long time for them to complete and start the upgrade on the last 2 agents. The network IO is very high, that’s why we would recommend a lower so the upgrade wouldn’t be network bound.
Picking 6 was better in our case. In two rounds all nodes are installed with limited network io.
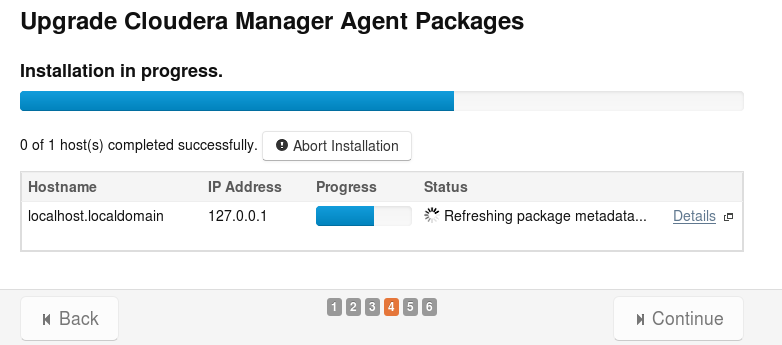
In our case the update failed after distributing the packages with the message:
cannot copy parcel.json to data node
The bars of all nodes were green, but the wizard could not continue or retry, we had to fix some issues…
The wizard shows that all CDH.5.0.3 parcels have been distributed to all the nodes.
We could not rerun the upgrade wizard, trying it again resulted in a cannot rerun upgrade wizard error.
Through the Cloudera Manager interface we could check the nodes:
The error suggested that the files are not present on the datanodes. We checked and the files were present on the datanodes mentioned in the error and the md5sum was the same as on the other nodes.
Try to start the service 1-by-1 from the Cloudera Manager.
Problem:
…
Caused by: MetaException(message:Version information not found in metastore. )
…
After some research:
CDH5 is shipped with Hive 0.12 an upgrade from Hive 0.10 (CDH4). For this update the database-schema should be updated. We suspected that the update script did not run, because the wizard did not complete. But where should we run what?
Where is the MetaStore database?
The settings contains the location and credentials to access the database used by the HiveMetastore server. In our case the HiveMetastore is located at data01, so we login on that machine to find and execute the update-scripts.
Solution:
Run the database upgrade scripts ourselves. There are upgrade scripts for the supported databases: derby, mysql, oracle and postgres. In each folder is a README which explains what needs to be done.
updatedb
locate CDH-5.0.3 | grep upgrade | grep mysql
cd /somewhere/CDH-5.0.3-1.cdh5.0.3.p0.35/lib/hive/scripts/metastore/upgrade/mysql/
mysql -u root hive1 -p
mysql> source upgrade-0.10.0-to-0.11.0.mysql.sql
mysql> source upgrade-0.11.0-to-0.12.0.mysql.sql
In Cloudera Manager we try to start the services again:
Great, no errors!
Alternative Solution
After manually upgrading the cluster in the way stated above, we discovered that it is also possible to use Cloudera Manager to run the upgrade on the individual services.
For HDFS:
For HIVE:
These steps should run the upgrade scripts that the upgrade wizard didn’t run. Hopefully you now have a working cluster again!
Let’s try to run our queries! Wait…Hue was started and accessible, but we could not login anymore.
Problem:
/hue/runcpserver.log
[16/Jul/2014 02:05:29 -0700] backend WARNING Caught LDAPError while authenticating alexanderbij: INVALID_CREDENTIALS({'info': 'Simple Bind Failed: NT_STATUS_LOGON_FAILURE', 'desc': 'Invalid credentials'},)
[16/Jul/2014 02:05:29 -0700] access WARNING 172.16.20.53 -anon- - "POST /accounts/login/ HTTP/1.1" --Failed login for user "alexanderbij"
In the log it is clear simple bind is used. We have configured samba4 on the cloudera-mgmt to not allow simple_bind, you need a valid kerberos ticket to validate users against samba/ldap.
This is not be a problem when you don’t have a Kerberos secured cluster.
In Cloudera Manager we checked the Hue config:
The Authentication Backend settings was LdapBackend, which did work in CDH 4.5.0 before the upgrade.
We noticed that the hue.ini from the HUE_SERVER does not have kerberos settings. The KT_RENEWER service hue.ini does have the correct kerberos settings. We are not sure if this is the root cause of the problem.
For this issue we have created a ticket:
HUE-2226, to be continued…
Solution:
The solution was to use PamBackend authentication instead. When logging into Hue the credentials are checked through the machine local linux Pluggable Authentication Modules (PAM).
Each node in the cluster has sssd authentication mechanism which hooks in as a PAM module and uses Kerberos and LDAP to authenticate.
In this blog we will not go into the details of this setup.
After restarting Hue with PamBackend, all users could login again.
Next problem:
The homescreen of Hue showed some warnings:
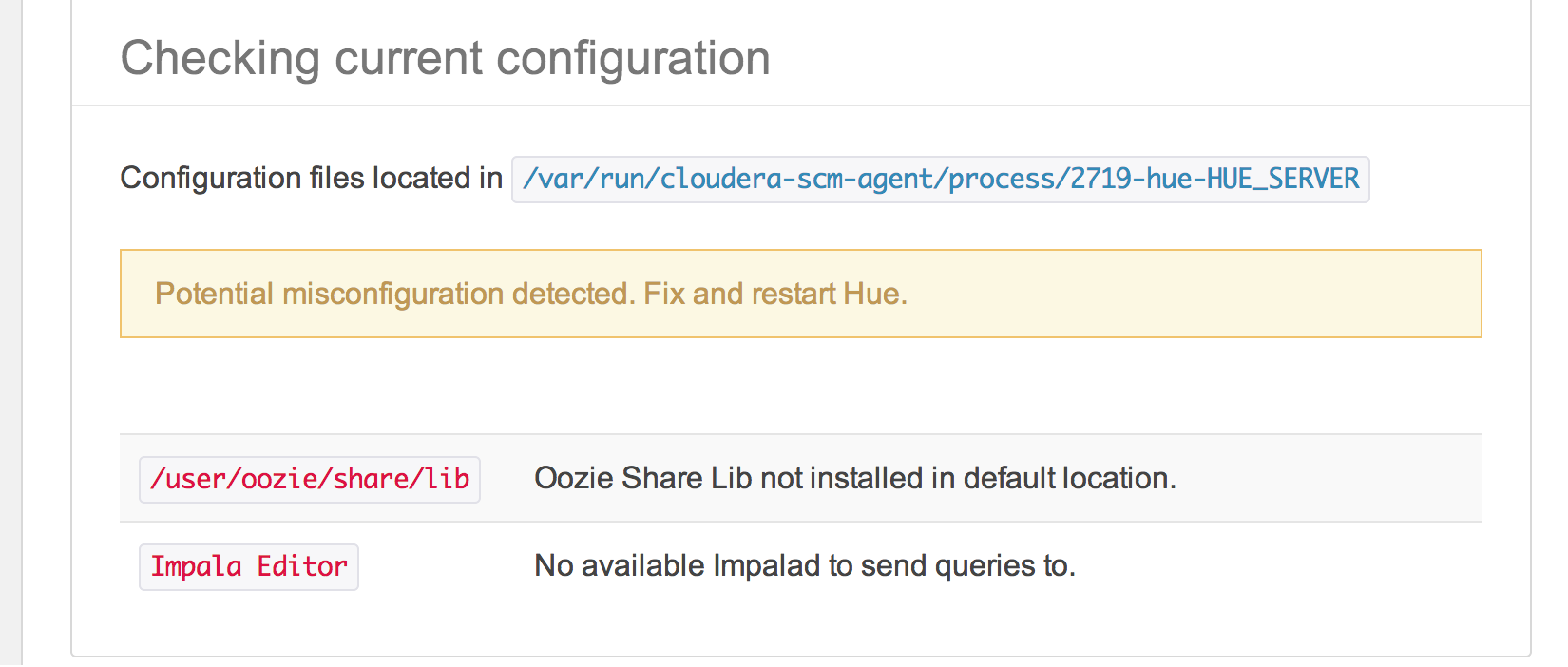
Running hive and impala queries (from HUE) did not work. Running queries from the commandline using hive and impala-shell did work. By checking server log from Hue in /hue/runcpserver.log we found:
INFO Thrift saw an application exception: Invalid method name: 'GetSchemas'
in the /hue/error.log:
ERROR Thrift saw exception (this may be expected).
Traceback (most recent call last):
File "/opt/cloud.....sktop/lib/thrift_util.py", line 367, in wrapper
ret = res(*args, **kwargs)
File "/opt/cloud...../gen-py/TCLIService/TCLIService.py", line 355, in GetSchemas
return self.recv_GetSchemas()
File "/opt/cloud../gen-py/TCLIService/TCLIService.py", line 371, in recv_GetSchemas
raise x
TApplicationException: Invalid method name: 'GetSchemas'
Solution:
It turns out that we had configured Hue Savety Valve for impala. Before the upgrade we followed a tutorial to use impala: Installing and using Impala with Hue.
Properties are pointing to port 21000 which is the port for the HiveServer1 protocol, but the newer version is using HiveServer2 protocol which is running on port 21050.
In the current version of the Cloudera Manager you can choose the impala service and you don’t need to specify the impala properties yourself.
In the Cloudera Manager:
[impala]
server_host=data05
server_port=21000
By removing this extra safety-valve config and choosing the Impala Service: impala1 at the Service-Wide category followed by a restart of hue the problem was solved.
The documentation of Cloudera is complete and adjusted for the different versions of the components. Most of the settings and configuration-files can be found there. The upgrade process is explained in detail.
Although upgrading sounds like a piece of cake, it wasn’t done without a fight. It was definitely worth upgrading even with all the bug-fixes, the user experience is greatly improved and we’re using the latest and greatest again. All users of the cluster are happy with the new version.
The main take away is that if the upgrade wizard fails, which sadly has been the case on both this production cluster and a VM test cluster, it can not be rerun. The idea is to manually perform all the steps that the wizard failed to do.

